Resumen técnico
Qumulo Core es una plataforma de datos de archivos de alto rendimiento. Así es como funciona.
Descargar este recurso
Nuestra misión: capacitar a creadores e innovadores
Nuestro objetivo en Qumulo es hacer que lo complejo sea radicalmente simple. Queremos simplificar la protección de sus datos. Queremos simplificar la adopción de nuevas plataformas. Queremos simplificar el servicio de flujos de trabajo exigentes (a bajo costo). Queremos simplificar la nube híbrida.
La misión de Qumulo es ayudar a los innovadores a liberar el poder de sus datos dondequiera que residan. Los innovadores crean nuevos negocios, tratamientos, productos y arte al transformar los datos en valor. Esta transformación se basa en un ciclo de vida de los datos donde los colaboradores capturan, interactúan, transforman, publican y luego archivan sus datos. Dentro de este ciclo de vida, los “creadores” (artistas, investigadores, etc.) utilizan datos digitales para hacer su trabajo. Vemos esta transformación en acción en varias industrias.
Ciencias de la vida
Los científicos exploran los datos capturados de secuenciadores para identificar anomalías, luego los clústeres de cálculo transforman los datos sin procesar en descubrimientos terminados. Esos descubrimientos se publican en la comunidad de investigación y luego se archivan los datos.
Medios de Comunicación y Entretenimiento
Los artistas editan los datos capturados de las tomas diarias para crear escenas iniciales, luego renderizan las canalizaciones y las transforman en películas terminadas. Los distribuidores publican esa película en los puntos de venta en línea y el contenido final se archiva.
Fabricación e IoT
Los registros y las imágenes se generan a partir de sensores (con gran volumen, velocidad y variedad) y se analizan en tiempo real para detectar fallas en los componentes. Posteriormente, los analistas de negocios revisan los datos para explorar oportunidades de mejoras en los procesos y, por parte de los científicos de datos, para construir mejores modelos de aprendizaje automático. Esos modelos se publican en la línea de fabricación para mejorar la eficiencia de la producción, y los registros e imágenes terminados se archivan.
Requisitos de una plataforma de datos de archivos
Para innovar, las organizaciones dependen de plataformas de datos de archivos no estructurados. Estas plataformas brindan almacenamiento persistente para los datos que impulsan la innovación. Brindan acceso fácil, rápido y confiable a los creadores y granjas de cómputo que transforman los datos en descubrimiento. Los innovadores requieren que sus plataformas de datos no estructurados:
Esté preparado para la nube
Las plataformas deben construirse para infraestructuras de nube pública, privada e híbrida, ofreciendo servicios de datos no estructurados en la nube pública y en el centro de datos. También deben adaptarse perfectamente al ecosistema de servicios en la nube (por ejemplo, aprendizaje automático (ML), publicación o servicios de almacenamiento de objetos en la nube).
Escala
Las plataformas deben poder servir petabytes de datos, miles de millones de archivos, millones de operaciones y miles de usuarios.
Trabajar con herramientas estándar
Los creadores más valiosos de una organización innovadora (artistas, investigadores, científicos de datos y analistas) deben poder utilizar sus herramientas sin tener que instalar controladores personalizados o realizar cambios en su flujo de trabajo.
- Proporcionar visibilidad y automatización
Los administradores deben poder crear, administrar y eliminar servicios de datos mediante las API RESTful. Deben ser capaces de comprender el rendimiento y la utilización de la capacidad de sus servicios de datos en tiempo real para poder diagnosticar mejor los problemas y planificar el futuro.
- Seguro y listo para la empresa
Los datos son el elemento vital de las organizaciones innovadoras y, por lo tanto, deben protegerse mediante herramientas de cifrado e identidad estándar de la industria. La plataforma de datos debe satisfacer los requisitos de la empresa para la recuperación de desastres, la copia de seguridad y la gestión de usuarios.
Los desafíos de las soluciones existentes
Las organizaciones que prosperan con los datos para impulsar la innovación están mal atendidas por las plataformas de datos no estructurados disponibles.
Las plataformas de datos de archivos de código abierto y basadas en Windows escalan mal, son difíciles de aprovisionar automáticamente y requieren una administración sustancial.
Las plataformas de datos de archivos heredadas basadas en dispositivos de hardware carecen de funciones de visibilidad en tiempo real, ofrecen superficies de API incompletas y solo pueden admitir cargas de trabajo de nube pública a través de ofertas de hardware como servicio adyacente a la nube. Las variantes de escalado vertical, como NetApp, luchan por escalar espacios de nombres únicos más allá de los 100 TB.
Los servicios de archivos y objetos en la nube admiten muchas cargas de trabajo de innovación en la nube, pero no permiten a los creadores utilizar sus herramientas estándar, principalmente debido a la falta de compatibilidad con archivos multiprotocolo. Además, carecen de muchas de las características empresariales y de seguridad que requieren las organizaciones para trasladar las cargas de trabajo a la nube pública.
Los almacenes de objetos locales ofrecen almacenamiento de datos de bajo costo, pero son fundamentalmente inadecuados para las etapas interactivas y transformadoras del ciclo de vida de los datos debido al bajo rendimiento y la falta de soporte para las herramientas estándar del usuario final.
Arquitectura de software de Qumulo
Qumulo se fundó para capacitar a los creadores con una plataforma de datos no estructurada para nubes públicas y privadas.
Empaquetamos esa plataforma en productos escalables y listos para la nube que permiten a los creadores usar herramientas esenciales. También proporcionamos API sólidas para la administración y la visibilidad en tiempo real del uso del sistema, y cumplimos con los requisitos de seguridad y protección de datos de las empresas Fortune 500.
El propósito de este documento es proporcionar una descripción general de la arquitectura de la plataforma de datos de archivos de Qumulo para ilustrar cómo nuestro producto ofrece los beneficios mencionados anteriormente a los innovadores y creadores. Para ilustrar la diferenciación arquitectónica y el valor de nuestra plataforma, exploraremos las capas principales de nuestro software. En cada capa, describiremos el propósito de la capa, cómo entrega elementos de nuestra propuesta de valor y la innovación que impulsa ese valor.
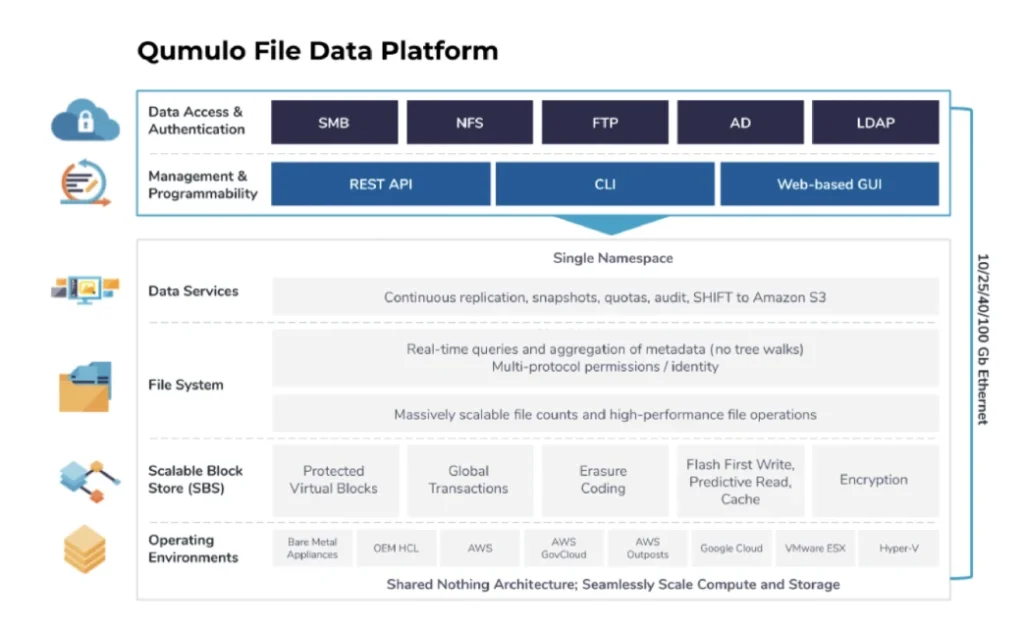
Fundamentos de la plataforma de datos de archivos Qumulo
Antes de sumergirse en los componentes individuales de la plataforma de datos de archivos, existen varias suposiciones fundamentales que son importantes para comprender la arquitectura de Qumulo:
1. Qumulo proporciona un sistema distribuido que presenta un único espacio de nombres. La plataforma de datos de archivos de Qumulo consiste en grupos de nodos independientes que no comparten nada. Cada nodo proporciona capacidad y rendimiento. Los nodos individuales se mantienen en constante coordinación entre sí. Cualquier cliente puede conectarse a cualquier nodo y leer y escribir en el espacio de nombres.
2. La plataforma de datos de archivos de Qumulo está optimizada para escalar. Nos aseguramos de que todos los aspectos de nuestro producto puedan admitir cómodamente petabytes de datos, miles de millones de archivos, millones de operaciones y miles de usuarios.
3. La plataforma de datos de archivos de Qumulo tiene una alta disponibilidad y es inmediatamente consistente. La plataforma de datos no estructurados de Qumulo está diseñada para soportar fallas de componentes en la infraestructura y al mismo tiempo brindar un servicio confiable a los clientes. Hacemos esto mediante el uso de abstracción de software, codificación de borrado, tecnologías de redes avanzadas y pruebas rigurosas. Cuando los datos se escriben en el software de Qumulo, no reconocemos esa escritura en el servicio, el usuario o el nodo de cómputo hasta que hayamos almacenado esos datos en un almacenamiento persistente. Por lo tanto, cualquier lectura será de una vista coherente de los datos (a diferencia de los modelos eventualmente consistentes).
4. Qumulo ofrece software creado para la nube pública, privada e híbrida. El software de Qumulo hace pocas suposiciones sobre la plataforma en la que se ejecuta. Abstrae los recursos de hardware físicos o virtuales subyacentes para aprovechar la mejor infraestructura de nube pública y privada. Esto nos permite aprovechar la rápida innovación en tecnologías informáticas, de redes y de almacenamiento impulsadas por los proveedores de la nube y el ecosistema de fabricantes de componentes.
5. La plataforma de datos de archivos de Qumulo es API-first. Cada capacidad creada por Qumulo emerge primero como puntos finales de API. Luego presentamos un conjunto seleccionado de esos puntos finales en nuestra interfaz de línea de comandos (CLI) y nuestra interfaz visual. Esto incluye la creación de sistemas, la gestión de datos, el análisis de rendimiento y capacidad, la autenticación y la accesibilidad a los datos.
6. Qumulo envía software nuevo con rapidez y regularidad. Lanzamos nuevas versiones de nuestro software cada dos semanas. Esto nos permite responder rápidamente a los comentarios de los clientes, impulsar la mejora constante de nuestro producto e insistir en el código de calidad de producción de nuestros equipos.
7. El equipo de éxito del cliente de Qumulo es muy receptivo, está conectado y es ágil. Cada plataforma de datos de archivos de Qumulo tiene la capacidad de conectarse al monitoreo remoto a través de nuestro servicio de monitoreo basado en la nube Mission Qontrol. Nuestro equipo de éxito del cliente utiliza esos datos para ayudar a los clientes a superar incidentes, proporcionar información sobre el uso del producto y alertar a los clientes cuando sus sistemas experimentan fallas en los componentes. Esta combinación de soporte inteligente e innovación rápida de productos impulsa un puntaje NPS líder en la industria de más de 80.
Acceso y autenticación de datos
Propósito
Habilite el acceso a los datos utilizando aplicaciones estándar y sistemas operativos al tiempo que garantiza un control de identidad de nivel empresarial.
Cómo funciona
Nuestra capa de acceso a datos admite los tres protocolos de acceso a archivos más comúnmente adoptados por los creadores (NFS, SMB y FTP). Estos protocolos existen como recursos independientes y escalables en cada nodo de un clúster de Qumulo. Los usuarios finales ven un único espacio de nombres que puede expandirse en capacidad y rendimiento. Se puede acceder a este espacio de nombres sin problemas desde cualquier dispositivo informático Windows, Mac o Linux y, por lo tanto, cualquier aplicación de datos no estructurada.
Nuestra capa de autenticación admite los dos servicios de identidad estándar de la industria: Active Directory (AD) y Lightweight Directory Access Protocol (LDAP). Los servicios de datos de Qumulo se integran con estos sistemas de identidad globales administrados por los clientes, lo que permite controlar el acceso a través de la computación, los usuarios finales y los datos. La conexión de la plataforma de datos de archivos de Qumulo a los servicios de identidad requiere una configuración simple y funciona bien con configuraciones de servicios de identidad distribuidas y complejas (un desafío común en los entornos de nube pública y privada de las empresas).
Cada protocolo de acceso a datos utiliza una capa de autenticación común para interactuar con los datos almacenados en nuestra plataforma de datos de archivos. Esto permite a los usuarios moverse entre aplicaciones, sistemas operativos y entornos, todo mientras acceden a los mismos datos. A medida que los datos se mueven a través del ciclo de vida de los datos (desde la captura hasta la transformación y el archivo), esta separación de capas ofrece una flexibilidad crítica y reduce la cantidad de sistemas que los clientes necesitan mantener.
Puntos de innovación
Los protocolos de acceso a datos de Qumulo permiten a los usuarios aprovechar cualquier sistema operativo estándar de Windows, Mac o Linux y cualquier aplicación estándar sin realizar cambios en su entorno.
Qumulo admite protocolos de acceso a datos con estado (SMB) y sin estado (NFS) desde el mismo espacio de nombres escalable.
Qumulo permite la gestión de identidades de nivel empresarial en un sistema escalable con alta disponibilidad.
Gestión y programabilidad
Propósito
Permita que los propietarios de aplicaciones creen soluciones integradas con la plataforma de datos de archivos Qumulo y permita a los administradores automatizar y administrar sus servicios de datos.
Cómo funciona
La capa de gestión y capacidad de programación se compone de tres capacidades; una API REST, una interfaz de línea de comandos (CLI) y una interfaz visual.
La API REST
La API REST es un superconjunto de todas las capacidades de la plataforma de datos Qumulo. Desde la API, los clientes pueden:
- Cree un espacio de nombres (en la nube usando una plantilla de Terraform o Cloud Formation)
- Configure todos los aspectos de un sistema (desde la seguridad, como los servicios de identidad o los roles de gestión, hasta la gestión de datos, como las cuotas, la protección de datos, como las políticas de instantáneas o la replicación de datos, y la adición de nueva capacidad).
- Recopilar información sobre su sistema (incluida la utilización de la capacidad y los puntos críticos de rendimiento)
- Acceso a datos (incluidas operaciones de lectura y escritura)
La API se "autodocumenta", lo que facilita a los desarrolladores y administradores explorar cada punto final (y ver los resultados de ejemplo). Qumulo mantiene una colección de usos de muestra de nuestra API en Github (https://qumulo.github.io/).
La interfaz de línea de comandos (CLI)
La CLI de Qumulo ofrece la mayor parte (pero no toda) de la API y se centra en los administradores del sistema. La CLI ofrece un método de interacción programable para trabajar con un sistema Qumulo. La CLI ofrece aproximadamente 200 comandos únicos (a partir de Qumulo Core Versión 3.0.3). Puede encontrar una lista completa de comandos en nuestra Base de conocimientos (www.care.qumulo.com).
La interfaz visual
La interfaz visual de Qumulo ofrece una forma centrada en el usuario de interactuar con una plataforma de datos de archivos de Qumulo. La interfaz visual es una interfaz basada en web, servida desde el sistema, sin necesidad de una máquina virtual o servicio por separado. La interfaz visual está organizada en torno a seis secciones de navegación de nivel superior: Tablero, Análisis, Compartir, Clúster, API y herramientas y Soporte.
Panel De Control
Esta es la "página de inicio" de la interfaz visual de Qumulo. Ofrece una serie de conocimientos fácilmente digeribles sobre la actividad, el crecimiento, el rendimiento y el estado de una plataforma de datos de archivos Qumulo. El panel visualiza la capacidad disponible y utilizada (incluidos datos, metadatos e instantáneas), el crecimiento de la capacidad y el crecimiento del recuento de archivos, el rendimiento agregado del sistema y el equilibrio de las cargas de trabajo.
Análisis
Esta sección ofrece a los administradores de sistemas una vista granular y en tiempo real de sus sistemas que no está disponible en otras plataformas de datos de archivos. Estos análisis ofrecen visibilidad y conocimiento de la utilización del rendimiento de cada carga de trabajo (ya sea por cliente o por ruta de datos) y en el crecimiento de la capacidad de su sistema, incluida una vista de qué partes de la plataforma de datos de archivos están creciendo o disminuyendo por período de tiempo. permitiendo a los clientes averiguar qué cargas de trabajo consumen su capacidad.
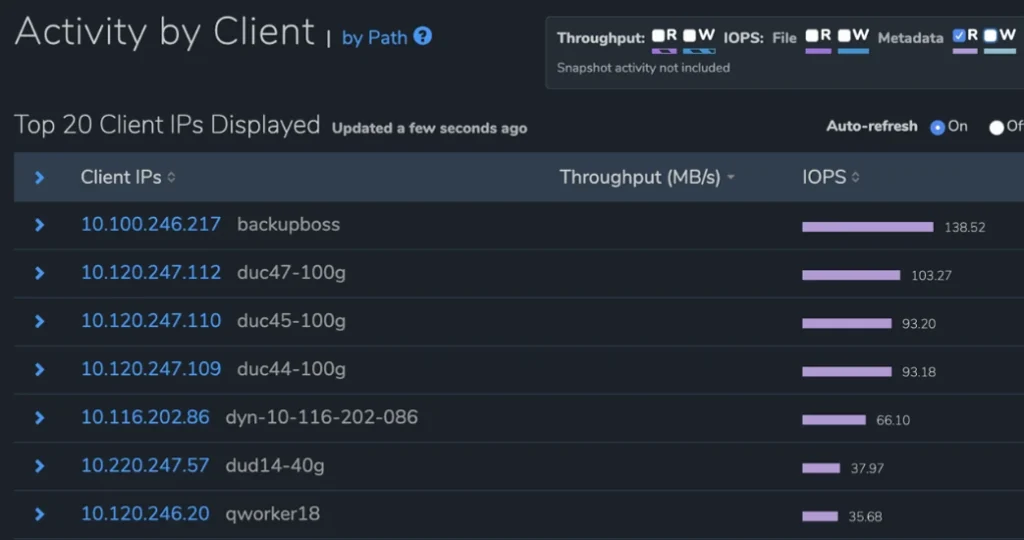
Compartir
Esta sección permite a los administradores hacer que los datos sean accesibles para los usuarios mediante la creación de recursos compartidos SMB y exportaciones NFS. También permite a los administradores gestionar el uso de la capacidad mediante cuotas. Finalmente, la sección de uso compartido es donde los administradores van a administrar la conexión del clúster a los servicios de identidad de AD y LDAP.
Médico
Esta sección permite a los administradores configurar políticas de instantáneas, políticas de replicación continua, redes y servicios de fecha y hora. Les permite ver los nodos del sistema y agregar nuevos nodos.
API y herramientas
Esta sección permite a los clientes descargar la herramienta de línea de comandos Qumulo y explorar nuestra API autodocumentada. Incluye la capacidad de "probar" cada punto final y ver ejemplos de salidas JSON.
Asistencia
Esta sección permite a los clientes realizar actualizaciones de software con Qumulo Instant Upgrade, conectarse al monitoreo remoto y autorizar al equipo de éxito del cliente de Qumulo a conectarse de forma remota a un sistema Qumulo.
Puntos de innovación
La API de Qumulo ofrece un superconjunto completo de todas las capacidades en la plataforma de datos de archivos de Qumulo, lo que permite a los clientes desarrollar contra el software de Qumulo y administrar su sistema Qumulo por completo a través de herramientas modernas de administración de infraestructura.
La interfaz visual de Qumulo ofrece herramientas simples (y comprensibles) para administrar los sistemas Qumulo, que reducen los gastos de TI en términos de costo y tiempo.
El panel y la interfaz visual de análisis brindan información procesable en tiempo real sobre cualquier plataforma de datos de archivos de Qumulo. Los usuarios pueden comprender qué tan bien su plataforma de datos de archivos Qumulo está sirviendo a los creadores y ofrece información sobre las cargas de trabajo de esos creadores.
Servicios de datos
Propósito
Proteja, asegure y administre los datos en la plataforma de archivos Qumulo utilizando las herramientas de nivel empresarial que los CIO y CSO esperan de las plataformas de datos.
Cómo funciona
La capa de servicios de datos se compone de cinco capacidades: instantáneas, replicación, cuotas, auditoría, control de acceso basado en roles (RBAC) y cambio a Amazon S3.
Snapshots
Los datos almacenados en una plataforma de datos de archivos Qumulo se pueden ver tanto en su forma actual como en versiones anteriores a través de instantáneas. Estas instantáneas utilizan una metodología única de escritura fuera de lugar que solo consume espacio cuando se producen cambios. Esto hace que las instantáneas de Qumulo sean tanto eficientes como eficaces. Las instantáneas se controlan mediante una política de instantáneas que articula la parte del espacio de nombres que se protegerá, la frecuencia de las instantáneas y el tiempo que se guardan las instantáneas.
Las políticas de instantáneas se pueden vincular con políticas de replicación. Esto permite que las instantáneas se repliquen en una segunda plataforma de datos de archivos de Qumulo y que las instantáneas frecuentes se mantengan en una plataforma de datos de archivos de Qumulo y las instantáneas menos frecuentes en otra (una estrategia común de protección contra ransomware y pérdida de datos empresariales). Los administradores pueden restaurar instantáneas y los archivos individuales pueden restaurarse a través de la interfaz visual / CLI / API, o directamente por los usuarios finales a través de herramientas de cliente (por ejemplo, "Versiones anteriores" en Windows). El límite en el número total de instantáneas en una plataforma de datos de archivo Qumulo se mide en decenas de miles, más alto que la mayoría de los otros sistemas.
Replicación
La replicación permite a los usuarios copiar, mover y sincronizar datos en múltiples plataformas de datos de archivos de Qumulo. Nuestra tecnología de replicación ofrece dos capacidades principales: movimiento de datos eficiente e identificación granular de datos modificados. La replicación de Qumulo es continua, lo que significa que cualquier cambio nuevo en un directorio replicado será identificado y movido, asincrónico y unidireccional. Nuestra tecnología de replicación aprovecha las instantáneas para crear una lista de regiones de archivos modificadas en un período de tiempo determinado, que luego se trasladan a una segunda plataforma de datos de archivos Qumulo a través de un protocolo de transferencia de datos cifrados. La lista de archivos modificados está disponible como su propio punto final de API, que los ISV de terceros utilizan para integrar Qumulo en los sistemas de respaldo de datos. La replicación de Qumulo funciona en dos plataformas de datos de archivos de Qumulo, incluidas local a nube, nube a nube y en regiones de nube. La replicación se utiliza para habilitar la copia de seguridad a escala de petabytes, especialmente cuando se combina con la recuperación ante desastres de replicación de instantáneas, incluida la conmutación por error y la conmutación por recuperación. También permite la nube híbrida y el estallido de la nube, la infraestructura multinube y multirregional y escenarios de colaboración remota.
Cambio de Qumulo a Amazon S3
La replicación del almacén de objetos permite que cualquier plataforma de datos de archivos de Qumulo trate un servicio de almacenamiento de objetos en la nube (por ejemplo, Amazon S3) como un objetivo de replicación adecuado. Los usuarios pueden copiar datos de un espacio de nombres de Qumulo a un almacén de objetos en la nube a través de Qumulo Shift una vez, o de forma continua, y viceversa. Los datos que se mueven a un almacén de objetos se almacenan en un formato abierto y no propietario que permite a los creadores aprovechar esos datos a través de aplicaciones que se conectan directamente al almacén de objetos en la nube de Amazon S3, en formato nativo de Amazon S3. Los escenarios de ejemplo incluyen archivar datos de un espacio de nombres de Qumulo en niveles de almacenamiento en frío de objetos en la nube de Amazon S3, o permitir que los servicios de aprendizaje automático basados en datos de Amazon S3 procesen datos que fueron capturados y editados en una plataforma de datos de archivos de Qumulo.
Cuotas
Las cuotas permiten a los usuarios controlar el crecimiento de cualquier subconjunto de un espacio de nombres de Qumulo. Las cuotas actúan como límites independientes en el tamaño de cualquier directorio, evitando el crecimiento de datos cuando se alcanza el límite de capacidad. A diferencia de otros productos, las cuotas de Qumulo surten efecto de forma instantánea, lo que permite a los administradores identificar cargas de trabajo no autorizadas utilizando nuestro análisis de capacidad en tiempo real y detener instantáneamente el uso desenfrenado de la capacidad. Las cuotas incluso siguen la parte del espacio de nombres que cubren cuando los directorios se mueven o se les cambia el nombre.
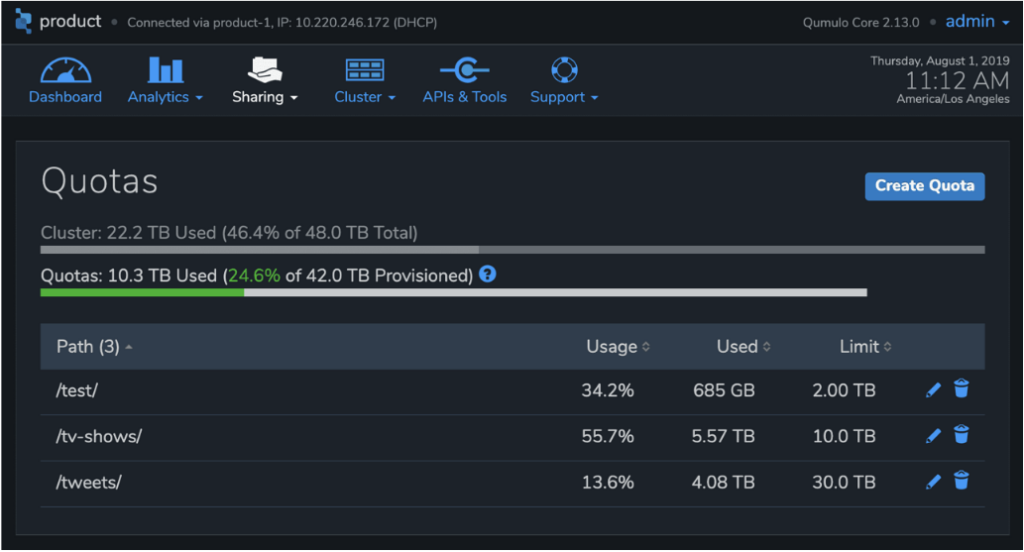
Auditoría
La auditoría permite a los administradores de seguridad realizar un seguimiento de todas las acciones realizadas en un espacio de nombres de Qumulo y los cambios de configuración en el sistema. Audit captura todos los accesos y modificaciones de datos, intenta acceder a una plataforma de datos de archivos de Qumulo, comparte datos a través de nuevos recursos compartidos o exportaciones y cambios en la configuración del sistema o esquemas de protección de datos. Audit envía esos registros de actividad a cualquier servidor syslog remoto estándar.
Control de acceso basado en roles
El control de acceso basado en roles (RBAC) permite a los administradores de seguridad utilizar sus servicios de identidad para controlar qué usuarios o grupos tienen derechos para realizar cambios en una plataforma de datos de archivos Qumulo o ver la interfaz visual. RBAC ofrece varios "roles" preconfigurados que tienen derechos para tomar medidas en el sistema (administrador, observador, administrador de datos). Los administradores agregan usuarios y grupos de AD o LDAP a esos roles. Los administradores también pueden crear roles personalizados para que coincidan con los regímenes de seguridad únicos en su organización (por ejemplo, un rol de "administrador de respaldo").
Puntos de innovación
Qumulo Shift copia los datos del archivo al formato de objeto nativo de Amazon A3 para que los servicios nativos de la nube de AWS puedan utilizar fácilmente los datos.
Las instantáneas en la plataforma de datos de archivos de Qumulo son eficientes, de alto rendimiento y escalables (a 40k o más).
La replicación de instantáneas permite realizar copias de seguridad integradas a escala de petabytes para cualquier plataforma de datos de archivos de Qumulo, sin importar dónde se encuentre.
La replicación permite que cualquier plataforma de datos de archivos de Qumulo copie, mueva o sincronice datos a cualquier otra plataforma de datos de archivos de Qumulo (desde local a la nube, región de nube a región de nube o entre nubes).
Las cuotas en Qumulo son en tiempo real y no requieren largas enumeraciones de la plataforma de datos (también conocidas como "caminatas en árbol") para que surtan efecto.
Audit se integra simplemente con herramientas modernas de administración de infraestructura como Splunk.
El sistema de archivos Qumulo
Propósito
Organice los datos en estructuras comprensibles, habilite cargas de trabajo con recuentos masivos de archivos, permita a los creadores colaborar en conjuntos de datos a medida que avanzan en el ciclo de vida de los datos y brinde información en tiempo real sobre el rendimiento y la utilización de la capacidad, incluso cuando los sistemas escalen a petabytes y miles de millones de archivos .
Cómo funciona
El sistema de archivos Qumulo organiza todos los datos almacenados en un sistema Qumulo en un espacio de nombres. Este espacio de nombres es compatible con POSIX y mantiene los permisos y la información de identidad que admiten la semántica completa disponible en los protocolos NFS o SMB. Como todas las plataformas de datos de archivos, la plataforma de datos de archivos Qumulo organiza los datos en directorios y los presenta a los clientes SMB y NFS. Sin embargo, la plataforma de datos de archivos Qumulo tiene varias propiedades únicas: el uso de árboles B, un motor de análisis en tiempo real y permisos de protocolo cruzado (XPP).
Árboles B en la plataforma de datos de archivos
La plataforma de datos de archivos Qumulo puede escalar a miles de millones de archivos sin experimentar los problemas comunes en otras plataformas, como quedarse sin inodos, ralentizaciones, ineficiencia y recuperación de fallas de componentes prolongadas. Logramos esto mediante el uso de una colección de tecnologías, una de las cuales es el árbol B. Los árboles B son particularmente adecuados para sistemas que leen y escriben grandes cantidades de bloques de datos porque son estructuras de datos “superficiales” que minimizan la cantidad de E / S requerida para cada operación a medida que aumenta la cantidad de datos. Con los árboles B como base, el costo computacional de leer o insertar bloques de datos crece muy lentamente a medida que aumenta la cantidad de datos.
Por ejemplo, los árboles B son ideales para plataformas de datos de archivos e índices de bases de datos muy grandes. En la plataforma de datos de archivos de Qumulo, los árboles B están basados en bloques. Cada bloque tiene 4096 bytes y cada bloque de 4K puede tener punteros a otros bloques de 4K. La plataforma de datos de archivos Qumulo utiliza árboles B para muchos propósitos diferentes. Hay un árbol B de inodo, que actúa como índice de todos los archivos. La lista de inodos es una técnica de implementación de plataforma de datos de archivo estándar que hace que la verificación de la coherencia de la plataforma de datos de archivo sea independiente de la jerarquía de directorios. Los inodos también ayudan a que las operaciones de actualización, como los movimientos de directorio, sean eficientes. Los archivos y directorios se representan como árboles B con sus propios pares clave / valor, como el nombre del archivo, su tamaño y su lista de control de acceso (ACL) o permisos POSIX. Los datos de configuración también son un árbol B y contienen información como la dirección IP del clúster.
Motor de análisis en tiempo real
Qumulo ofrece información sobre la utilización de la capacidad y el rendimiento de los datos en una plataforma de datos de archivos de Qumulo. Esto permite a los clientes ver, casi instantáneamente, qué partes de la plataforma de datos de archivos han crecido (o reducido), qué aplicaciones consumen recursos de rendimiento y qué partes de la plataforma de datos de archivos están más activas. Esto permite a los clientes solucionar problemas de aplicaciones, administrar el consumo de capacidad y planificar utilizando datos reales. Estos conocimientos se basan en dos tecnologías: agregación de metadatos de capacidad y muestreo de plataforma de datos de archivos.
Agregación de metadatos de capacidad
En la plataforma de datos de archivos Qumulo, los metadatos, como los bytes utilizados y los recuentos de archivos, se agregan como archivos y se crean o modifican directorios. Esto significa que la información está disponible para su procesamiento oportuno sin costosas caminatas en el árbol de la plataforma de datos de archivos. El motor de análisis en tiempo real mantiene resúmenes de metadatos actualizados en el espacio de nombres de la plataforma de datos de archivos. Utiliza los árboles B de la plataforma de datos de archivos para recopilar información sobre la plataforma de datos de archivos a medida que se producen cambios. Varios campos de metadatos se resumen dentro de la plataforma de datos de archivos para crear un índice virtual. A medida que ocurren los cambios, se recopilan nuevos metadatos agregados y los cambios se propagan desde los archivos individuales a la raíz de la plataforma de datos de archivos.
A medida que cada archivo (o directorio) se actualiza con nuevos metadatos agregados, su directorio principal se marca como desactualizado y se pone en cola otro evento de actualización para el directorio principal. De esta manera, la información de la plataforma de datos de archivos se recopila y agrega mientras se pasa al árbol. Los metadatos se propagan desde el nodo individual, en el nivel más bajo, hasta la raíz de la plataforma de datos de archivos a medida que se accede a los datos. Se contabiliza cada operación de archivo y directorio.
En paralelo a la propagación ascendente de los eventos de metadatos, un recorrido periódico comienza en la parte superior de la plataforma de datos de archivos y lee la información agregada presente en los metadatos. Cuando el recorrido encuentra información agregada actualizada recientemente, poda su búsqueda y pasa a la siguiente rama. Asume que la información agregada está actualizada en el árbol de la plataforma de datos de archivos desde este punto hacia las hojas, incluidos todos los archivos y directorios contenidos, y no es necesario profundizar más para obtener análisis adicionales. La mayor parte del resumen de metadatos ya se ha calculado e, idealmente, el recorrido solo necesita resumir un pequeño subconjunto de metadatos para toda la plataforma de datos de archivos. En efecto, las dos partes del proceso de agregación se encuentran en el medio sin tener que explorar el árbol completo de la plataforma de datos de archivos de arriba a abajo.
Muestreo del sistema de archivos
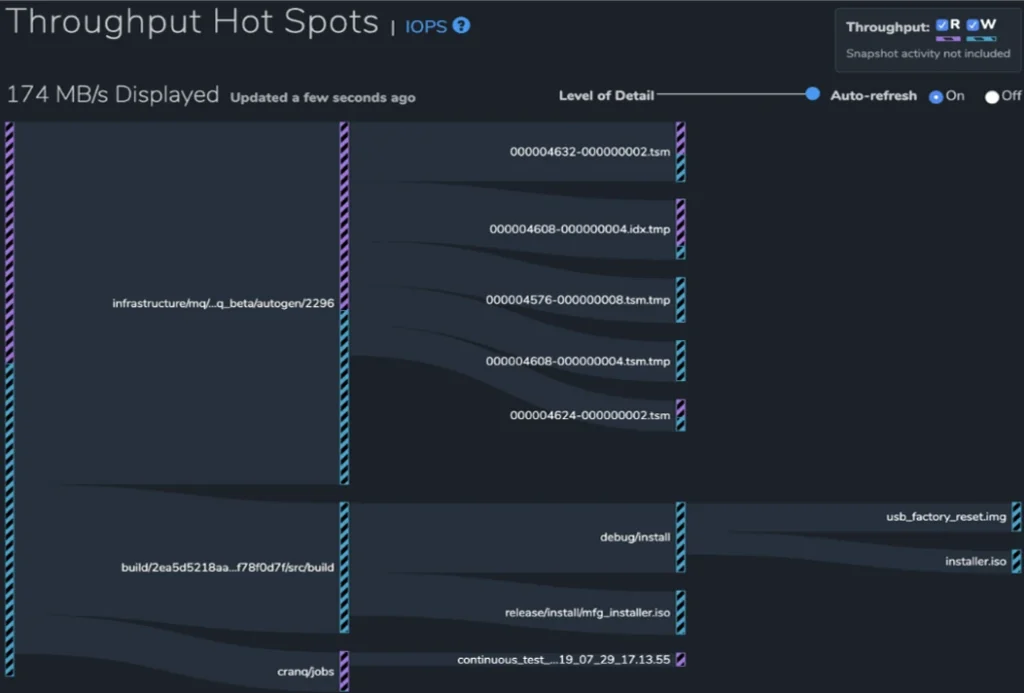
Un ejemplo de los análisis en tiempo real de Qumulo son sus informes de puntos críticos de rendimiento. Representar cada operación de rendimiento e IOPS dentro de la interfaz visual sería inviable en plataformas de datos de archivos grandes. En cambio, el motor de análisis en tiempo real de Qumulo utiliza un muestreo probabilístico para proporcionar una aproximación estadísticamente válida de esta información. Los totales para las operaciones de lectura y escritura de IOPS, así como las operaciones de lectura y escritura de rendimiento de E / S, se generan a partir de muestras recopiladas de un búfer en memoria de decenas de miles o más entradas que se actualizan cada pocos segundos.
El informe que se muestra muestra las operaciones que tienen el mayor impacto en el clúster. Estos se representan como puntos de acceso en la interfaz visual.
La capacidad de Qumulo para usar muestreo probabilístico estadísticamente válido solo es posible debido a los metadatos resumidos para cada directorio (bytes usados, conteos de archivos) que el motor de análisis en tiempo real mantiene continuamente actualizado.
Permisos entre protocolos (XPP)
Para que los creadores puedan compartir datos a lo largo del ciclo de vida de la innovación, Qumulo debe permitir que diversos sistemas operativos accedan a los mismos datos (por ejemplo, Windows, Mac, Linux). Sin embargo, esos sistemas se basan en NFS y SMB, que tienen lenguajes muy diferentes para expresar la identidad. Por ejemplo, un laboratorio podría crear datos usando un secuenciador genómico, que ejecuta Windows y, por lo tanto, expresar la identidad usando el rico lenguaje de ACE y ACL. Luego, un investigador podría analizar esos datos utilizando un cliente de Windows, que también usa SMB y, por lo tanto, comprende las ACL. En algún momento, el investigador querrá coordinar una operación de cómputo en paralelo utilizando un clúster HPC que ejecuta Linux, que espera permisos POSIX (por ejemplo, bits de modo). La organización de investigación se enfrentaría a la opción de simplificar todos los permisos al conjunto menos restrictivo, permitiendo así el acceso requerido, o mover datos a un espacio de nombres completamente separado, lo que interrumpiría el flujo de colaboración y aumentaría los costos de TI.
Qumulo resolvió este problema creando una plataforma de datos de archivos que puede traducir y racionalizar múltiples lenguajes de permisos, de modo que cualquier cliente vea los permisos que espera sin sacrificar la expresividad del protocolo. A esta tecnología la llamamos XPP. Los permisos de protocolo cruzado (XPP) habilitan flujos de trabajo de protocolo SMB y NFS mixtos al preservar las ACL de SMB, mantener la herencia de permisos y reducir la incompatibilidad de aplicaciones relacionada con la configuración de permisos.
Los permisos entre protocolos están diseñados para funcionar de las siguientes formas:
- Cuando no hay interacción entre protocolos, Qumulo opera precisamente según las especificaciones del protocolo.
- Cuando surgen conflictos entre protocolos, los permisos entre protocolos minimizan la probabilidad de incompatibilidades de aplicaciones.
- La habilitación de permisos entre protocolos no cambiará los derechos de los archivos existentes en un sistema de archivos. Los cambios solo pueden ocurrir si los archivos se modifican mientras el modo está habilitado.
Puntos de innovación
La plataforma de datos de archivos de Qumulo puede escalar a miles de millones de archivos al mismo tiempo que conserva una alta eficiencia, resistencia a fallas de componentes y alto rendimiento.
Los clientes pueden diagnosticar flujos de trabajo, identificar aplicaciones que se comportan mal, administrar el consumo de capacidad y planificar el futuro utilizando datos en tiempo real sobre el rendimiento y la utilización de la capacidad, incluso en plataformas de datos de archivos de miles de millones y escala de petabytes.
Los creadores pueden colaborar a lo largo del ciclo de vida de los datos, utilizando herramientas estándar para clientes de usuario final y computación HPC, desde el mismo espacio de nombres de Qumulo en virtud de permisos entre protocolos.
La plataforma de datos de archivos de Qumulo puede escalar a miles de millones de archivos al mismo tiempo que conserva una alta eficiencia, resistencia a fallas de componentes y alto rendimiento.
Los clientes pueden diagnosticar flujos de trabajo, identificar aplicaciones que se comportan mal, administrar el consumo de capacidad y planificar el futuro utilizando datos en tiempo real sobre el rendimiento y la utilización de la capacidad, incluso en plataformas de datos de archivos de miles de millones y escala de petabytes.
Los creadores pueden colaborar a lo largo del ciclo de vida de los datos, utilizando herramientas estándar para clientes de usuario final y computación HPC, desde el mismo espacio de nombres de Qumulo en virtud de permisos entre protocolos.
La tienda de bloques escalable
Propósito
Lleve la plataforma de datos de archivos Qumulo a cualquier entorno de nube pública y privada, habilite una escala masiva, garantice la coherencia en todo el sistema, proteja contra fallas de componentes y alimente cargas de trabajo interactivas y de alto rendimiento.
Cómo funciona
La base de la plataforma de datos de archivos Qumulo es Scalable Block Store (SBS). El SBS aprovecha varias tecnologías centrales para permitir escala, portabilidad, protección y rendimiento: un sistema de bloques virtualizados, codificación de borrado, un sistema de transacciones global y una caché inteligente.
El sistema de bloques virtuales
La capacidad de almacenamiento de un sistema Qumulo se organiza conceptualmente en un único espacio de direcciones virtuales protegido. Cada dirección protegida dentro de ese espacio almacena un bloque de bytes de 4K. Cada uno de esos "bloques" está protegido mediante un esquema de codificación de borrado para garantizar la redundancia ante una falla del dispositivo de almacenamiento. Toda la plataforma de datos de archivos se almacena dentro del espacio de direcciones virtuales protegido proporcionado por SBS, incluida la estructura del directorio, los datos del usuario, los metadatos de los archivos, los análisis y la información de configuración.
El almacén protegido actúa como una interfaz entre la plataforma de datos de archivos y los datos basados en bloques registrados en los dispositivos de bloques adjuntos. Estos dispositivos pueden ser dispositivos flash o discos duros, ya sea en un servidor dedicado en la nube privada o en un servidor virtual en la nube pública. Mediante el uso de bloques de 4K, el sistema de bloques virtuales permite un almacenamiento altamente eficiente de archivos de todos los tamaños (grandes a pequeños).
Codificación de borrado
Cada bloque virtual es parte de un grupo de protección más grande llamado Almacén protegido (o pstore), que aprovecha la codificación de borrado para distribuir y proteger datos a través de una plataforma distribuida de datos de archivos Qumulo. Ese pstore es el contenedor organizador para la protección de datos. Dentro y entre pstores, los bloques de datos aprovechan los algoritmos de Reed-Solomon para crear copias de "paridad" de los bloques de datos que se utilizan para reconstruir los bloques dañados por una falla de un componente. El número de bloques de paridad determina la redundancia del clúster; los clústeres más grandes requieren más redundancia que los más pequeños, ya que contienen más componentes que podrían fallar. Estos pstores luego se distribuyen a través de una plataforma de datos de archivos de Qumulo para controlar la falla de los componentes en un servidor virtual o físico con CPU, dispositivos de almacenamiento y redes.
La implementación de Qumulo de codificación de borrado, junto con nuestro espacio granular de direcciones virtuales, permite que la plataforma de datos de archivos de Qumulo reconstruya de manera rápida y predecible los datos de los componentes fallidos. Además, esto permite a los sistemas aprovechar los medios basados en disco y flash más densos disponibles en la nube pública y privada, y operar sistemas a gran escala con un rendimiento confiable y sólidas garantías de protección de datos. Por último, este sistema de protección permite a los clientes utilizar con confianza el 100% del espacio protegido disponible en un sistema Qumulo, en contraste con otros sistemas que funcionan mal o de manera impredecible más allá del ~ 80% de utilización.
El almacén protegido actúa como una interfaz entre la plataforma de datos de archivos y los datos basados en bloques registrados en los dispositivos de bloques adjuntos. Estos dispositivos pueden ser dispositivos flash o discos duros, ya sea en un servidor dedicado en la nube privada o en un servidor virtual en la nube pública. Mediante el uso de bloques de 4K, el sistema de bloques virtuales permite un almacenamiento altamente eficiente de archivos de todos los tamaños (grandes a pequeños).
Sistema de transacciones globales
Debido a que Qumulo es una plataforma distribuida de datos de archivos sin compartir que ofrece garantías inmediatas de coherencia, necesitamos un mecanismo para garantizar que cada nodo del sistema tenga una vista coherente de todos los datos. Logramos esto asegurándonos de que todas las lecturas y escrituras en el espacio de direcciones virtuales sean transaccionales.
Esto significa que cuando una operación de plataforma de datos de archivos requiere una operación de escritura que involucra más de un bloque, la operación escribirá todos los bloques relevantes o ninguno de ellos. Las operaciones de lectura y escritura atómicas son esenciales para la coherencia de los datos y la implementación correcta de protocolos de archivo como SMB y NFS. Para un rendimiento óptimo, SBS utiliza técnicas que maximizan el paralelismo y la computación distribuida al mismo tiempo que mantienen la coherencia transaccional de las operaciones de E / S. Por ejemplo, SBS está diseñado para evitar cuellos de botella en serie, donde las operaciones se realizarían en una secuencia en lugar de en paralelo. El sistema de transacciones de SBS utiliza principios del algoritmo ARIES comúnmente utilizado en bases de datos para transacciones sin bloqueo, incluido el registro de escritura anticipada, el historial repetido durante las acciones de "deshacer" y el registro de acciones de "deshacer".
Sin embargo, la implementación de transacciones de SBS tiene varias diferencias importantes con ARIES. SBS aprovecha el hecho de que las transacciones iniciadas por la plataforma de datos de archivos Qumulo son predeciblemente cortas, en contraste con las bases de datos de propósito general donde las transacciones pueden ser de larga duración. Un patrón de uso con transacciones de corta duración permite a SBS recortar con frecuencia el registro de transacciones para mayor eficiencia. Las transacciones de corta duración permiten un pedido de compromiso más rápido.
Además, las transacciones de SBS están altamente distribuidas y no requieren un orden total definido globalmente de números de secuencia de estilo ARIES para cada entrada del registro de transacciones. En cambio, los registros de transacciones son localmente secuenciales en cada uno de los bloques virtuales y se coordinan a nivel global, utilizando un esquema de ordenamiento parcial que tiene en cuenta las restricciones de ordenamiento de compromisos.
La ventaja del enfoque de SBS es que la cantidad mínima absoluta de bloqueo se utiliza para las operaciones de E / S transaccionales, y esto permite que los clústeres de Qumulo se amplíen a muchos cientos de nodos.
Almacenamiento en caché inteligente y búsqueda previa
La plataforma de datos de archivos Qumulo almacena miles de millones de archivos y petabytes de capacidad. Sin embargo, en un momento dado, solo una pequeña parte de esos datos se encuentra en el conjunto de trabajo activo de un creador o innovador. Para garantizar que esos creadores tengan el rendimiento más rápido posible y, por lo tanto, evitar que los clientes compren sistemas dispares para cada etapa del ciclo de vida de los datos, Qumulo ofrece varias garantías de rendimiento en nuestro producto:
1. Todos los metadatos, que son los que se leen con mayor frecuencia en cualquier conjunto de datos, residen en los medios duraderos más rápidos del sistema (es decir, flash).
2. Los bloques virtuales que se leen con frecuencia (según lo medido por un "índice de calor" patentado) se almacenan en flash, los bloques virtuales que se leen con poca frecuencia se mueven a medios más fríos si están disponibles.
3. A medida que se leen los datos, el sistema observa el comportamiento del cliente e inteligentemente obtiene nuevos datos en la memoria en el nodo más cercano al cliente para acelerar los tiempos de acceso. Hacemos esto a través de la aplicación inteligente de una serie de modelos predictivos que observan esquemas de nombres de datos, orden de nacimiento de datos y patrones de lectura dentro de archivos grandes. El sistema aprovecha de manera inteligente el modelo más efectivo para cualquier carga de trabajo y desactiva los modelos que son un desperdicio.
Cifrado en reposo
Qumulo encripta automáticamente todos los sistemas a nivel del sistema de protección utilizando el estándar industrial encriptación AES256 en el modo XTS. Con este método, todas las plataformas de datos de archivos de Qumulo están protegidas contra ataques a los componentes subyacentes. El sistema presenta una única llave maestra que se encuentra encima de varias llaves de datos y el cliente puede rotarla. La combinación de este cifrado basado en software con la gestión de identidades, RBAC, auditoría y cifrado del tráfico de replicación y SMB permite a los clientes cumplir con rigurosos requisitos de seguridad empresarial.
Actualización instantánea
Qumulo es una empresa de desarrollo de software ágil y, como resultado, lanzamos regularmente nuevas mejoras. Queremos que nuestros clientes puedan acceder rápida y fácilmente a estas nuevas mejoras.
Qumulo diseñó el proceso de actualización de Qumulo Core para que sea rápido y fácil. Qumulo Core está en contenedores, lo que nos permite actualizar un clúster completo, independientemente del tamaño, en 20 segundos. Al instalar un Qumulo Core secundario, eliminamos los retrocesos, ya que la funcionalidad y la estabilidad del Qumulo Core se pueden demostrar antes de que ocurra una actualización.
Escala dinámica
Qumulo cree que no se le debe impedir el acceso a la última tecnología. Los datos están creciendo rápidamente y necesita acceso a nuevas tecnologías para mantener el ritmo. Los proveedores heredados no pueden mantenerse al día con el soporte de software para nuevas innovaciones de hardware. Estos proveedores a menudo requieren actualizaciones de montacargas que requieren una migración de datos compleja y que requiere mucho tiempo y / o crean grupos de almacenamiento complejos que son difíciles de administrar.
Qumulo proporciona una escala dinámica con compatibilidad de nodos que le permite aprovechar el nuevo procesador, el almacenamiento y la memoria en las implementaciones existentes. Esta compatibilidad de nodos permite a los clientes continuar ampliando fácilmente sus clústeres con nuevas generaciones de sistemas. Todos los sistemas Qumulo tendrán un camino de expansión a nuevas generaciones de hardware y una configuración más densa.
Puntos de innovación
Qumulo SBS abstrae los componentes de hardware subyacentes, lo que permite que la plataforma de datos de archivos de Qumulo se ejecute en entornos de nube pública y privada.
SBS de Qumulo ofrece un almacenamiento excepcionalmente eficiente en todos los tamaños de archivos.
La combinación de un sistema de bloques virtualizado y codificación de borrado permite a los clientes usar todo su espacio disponible y aprovechar los dispositivos de almacenamiento más densos que se ofrecen en la nube pública y privada.
Qumulo SBS permite a los clientes construir cómodamente sistemas muy grandes. Nuestro límite a partir de marzo de 2020 es de 100 nodos y 36 PB en un espacio de nombres, aunque aumentar ese límite es una función de las pruebas, no de la arquitectura.
El sistema de transacciones globales de Qumulo permite un rendimiento escalable masivamente con un bloqueo distribuido altamente eficiente para garantizar una coherencia inmediata.
El almacenamiento en caché predictivo y la captación previa de aprendizaje automático de Qumulo permiten un alto rendimiento en los datos más activos y, al mismo tiempo, permiten que los sistemas escalen lo suficiente para cubrir todo el ciclo de vida de los datos de innovación.
Qumulo Instant Upgrade permite que los clústeres de cualquier tamaño se actualicen en 20 segundos, eliminando la planificación previa y el monitoreo constante de la mayoría de las actualizaciones de infraestructura.
Conclusión
Qumulo creó una plataforma de datos de archivos que puede cubrir todo el ciclo de vida de los datos, desde la captura, pasando por la transformación, hasta el archivo en la nube pública y privada. Para lograr esto, Qumulo proporciona un sistema que está listo para la nube, escalable y fácil de usar. permite a los creadores utilizar herramientas estándar, proporciona capacidades de automatización y visibilidad, es seguro y está preparado para la empresa.
Listo para la nube
La plataforma de datos de archivos Qumulo está disponible en la nube pública, privada e híbrida.
Escala
La plataforma de datos de archivos Qumulo escala con confianza a miles de millones de archivos y petabytes de datos. La plataforma de datos de archivos Qumulo también escala en rendimiento para satisfacer las demandas de las cargas de trabajo más desafiantes.
Herramientas estándar
La plataforma de datos de archivos Qumulo es compatible con clientes de Windows, Mac y Linux.
Automatización y visibilidad
La plataforma de datos de archivos Qumulo proporciona una API robusta para la programación y la automatización y una visión en tiempo real de la utilización de la capacidad y el rendimiento del sistema.
Seguro y listo para la empresa
La plataforma de datos de archivos Qumulo ofrece las herramientas de identidad, control, administración y encriptación que las empresas requieren de su infraestructura.
Ver Qumulo en acción con una demo
Descubra lo sencillo que es gestionar datos de archivos a escala masiva en entornos de nube híbrida