Scripting Qumulo con S3 a través de Minio
En Qumulo, asegurarnos de que los clientes puedan acceder y administrar sus datos con facilidad es muy importante, ya que trabajamos para cumplir nuestra misión de convertirnos en la empresa en la que el mundo confía para almacenar sus datos para siempre. Durante mucho tiempo, los usuarios han podido interactuar con sus datos a través de las API de SMB, NFS y RESTful. Para la mayoría de los clientes, estos protocolos satisfacen sus necesidades. Sin embargo, un subconjunto cada vez mayor de nuestros clientes buscan hablar con su Qumulo a través de una API compatible con S3 para aprovechar la economía y el rendimiento del almacenamiento de archivos con herramientas modernas escritas para objetos.
Analytics - explorador de capacidad
Analytics: tendencias de capacidad
Analytics: análisis integrado
Analytics: puntos calientes de IOPS
Analítica: puntos calientes de rendimiento
Actividad analítica por ruta
Actividad analítica por cliente
Replicación continua
Configure la red para direcciones estáticas
Crear un clúster Qumulo en una Mac
Crear un clúster Qumulo en Windows
Crea una cuota
Crear una exportación NFS
Crear un recurso compartido SMB
Crear instantáneas con el panel de control de Qumulo
Apagado seguro
Scripting Qumulo con S3 a través de Minio
El almacenamiento de objetos es una opción cada vez más popular para los clientes que buscan almacenar sus datos en la nube. Incluso para los clientes que no buscan aprovechar el almacenamiento de objetos, muchas de las herramientas que están empezando a usar suponen un backend de objeto y se comunican a través de la API S3 de Amazon (que se ha convertido en el estándar de facto en las API de almacenamiento de objetos).
Para los clientes que desean interactuar con Qumulo a través del SDK o API de S3, recomendamos utilizar Minio. Minio es un servidor de almacenamiento de objetos de alto rendimiento que actúa como una interfaz compatible con S3 para diferentes nubes y almacenamiento local. Esto significa que puede hacer que un servidor Minio se siente frente a su almacenamiento Qumulo y maneje las solicitudes de S3.
En este tutorial, asumo que ya tiene una configuración de clúster Qumulo. Si ese no es el caso, siga este tutorial primero.
Modelo de liberación
Para un rendimiento óptimo, se recomienda el modelo de pasarela distribuida de Minio. Al usar un equilibrador de carga o un DNS round-robin, se pueden girar y conectar varias instancias de Minio al mismo NAS. El equilibrador de carga puede distribuir solicitudes de aplicaciones a través de un grupo de servidores Minio que hablan a través de NFS con Qumulo. Desde la perspectiva de sus aplicaciones, están hablando con S3, mientras que Qumulo solo ve varios clientes NFS conectados a él, por lo que no debe preocuparse por el bloqueo.
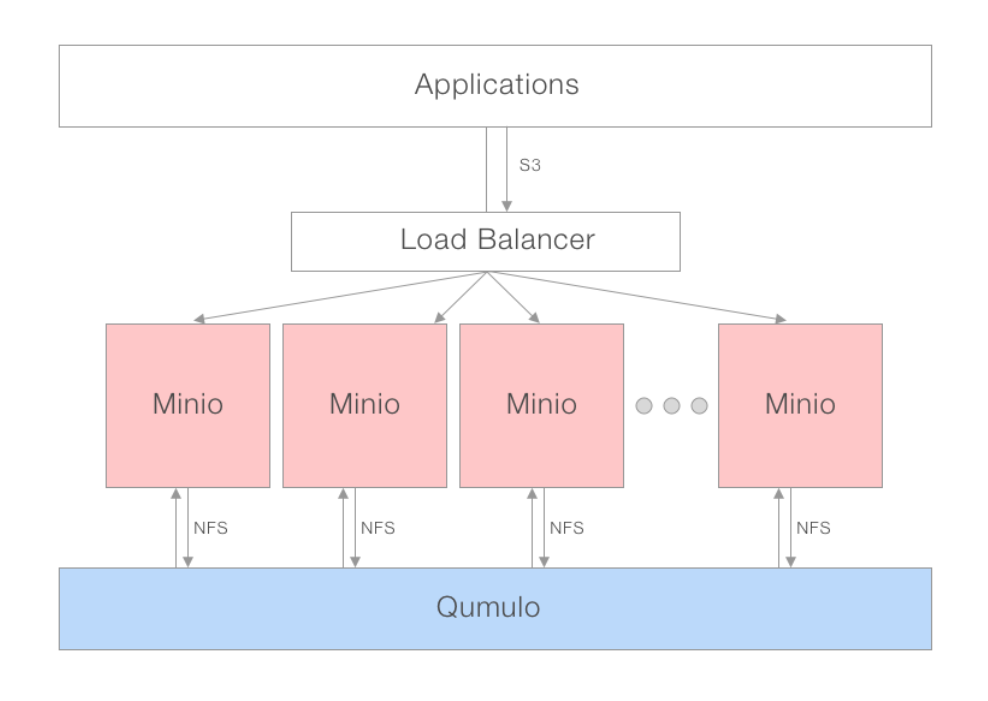
Ambiente recomendado
Nodos Qumulo: Todos los productos Qumulo son compatibles con Minio
Qumulo Client / Minio Server: 4 x uC-small (mc-14,15,18,19)
Montajes: Cada cliente tiene cada nodo Qumulo montado con argumentos NFS predeterminados
Servidor de Minio: instancias de 4 que se ejecutan a través de Docker en cada máquina cliente
Cliente de Minio (mc): Ejecutando x86 nativo en cada máquina del servidor Minio
Tutorial
Descargar minio
Vamos a empezar descargando Minio. Minio está disponible para todos los principales sistemas operativos, e incluso puede ejecutarse como un contenedor Docker o Kubernetes.
Docker
$> docker pull minio/minio
Linux
$> wget https://dl.minio.io/server/minio/release/linux-amd64/minio
$> chmod +x minio
MacOS
$> brew install minio/stable/minio
Windows
Descargar e instalar a través de https://dl.minio.io/server/minio/release/windows-amd64/minio.exe
Windows
Descargar e instalar a través de https://dl.minio.io/server/minio/release/windows-amd64/minio.exe
Ejecutando Minio en modo Gateway
Dentro de cada contenedor Docker en sus clientes, gire una instancia de Minio con el siguiente comando:
Docker
$> docker run -d -p 9000:9000 -e "MINIO_ACCESS_KEY=minio" -e "MINIO_SECRET_KEY=minio123" --name minio -v /mnt/minio-test:/nas minio/minio gateway nas /nas
Linux
./minio gateway nas ./Path-To-Mounted-Qumulo
MacOS
minio gateway nas ./Path-To-Mounted-Qumulo
Windows
minio.exe gateway nas X:\Path-To-Mounted-Qumulo
Prueba de que está funcionando
Para probar que su servidor Minio está funcionando, descargaremos Boto, el SDK de Python de S3 y escribiremos un script simple.
$> pip3 install boto3
Voy a crear un script de prueba en Python llamado "minio-test.py". En el interior escribí el siguiente código. Utiliza Boto3 para leer el archivo 'minio-read-test.txt' almacenado en la carpeta 'minio-demo' e imprime el contenido del archivo en la consola.
import boto3
from botocore.client import Config
# Configure S3 Connection
s3 = boto3.resource('s3',
aws_access_key_id = 'YOUR-ACCESS-KEY-HERE',
aws_secret_access_key = 'YOUR-SECRET-KEY-HERE',
endpoint_url = 'YOUR-SERVER-URL-HERE',
config=Config(signature_version='s3v4'))
# Read File
object = s3.Object('minio-demo', 'minio-read-test.txt')
body = object.get()['Body']
print(body.read())
Un ejemplo de código completo que muestra cómo puede realizar operaciones adicionales de S3 se puede encontrar a continuación.
Conclusión
Minio es un proyecto de código abierto estable y muy popular que promociona 105 millones de descargas. El proyecto es popular entre una comunidad extremadamente activa, lo que nos emociona de que los clientes lo implementen en sus entornos. También estamos entusiasmados porque tomamos en serio los comentarios de nuestros clientes, y la implementación de Minio como interfaz para Qumulo responde a una solicitud superior para una capa de compatibilidad S3.
Ejemplo de código completo
# Import AWS Python SDK
import boto3
from botocore.client import Config
bucket_name = 'minio-test-bucket' # Name of the mounted Qumulo folder
object_name = 'minio-read-test.txt' # Name of the file you want to read inside your Qumulo folder
# Configure S3 Connection
s3 = boto3.resource('s3',
aws_access_key_id = 'YOUR-ACCESS-KEY-HERE',
aws_secret_access_key = 'YOUR-SECRET-KEY-HERE',
endpoint_url = 'YOUR-SERVER-URL-HERE',
config=Config(signature_version='s3v4'))
# List all buckets
for bucket in s3.buckets.all():
print(bucket.name)
input('Press Enter to continue...\n')
# Read File
object = s3.Object(bucket_name, object_name)
body = object.get()['Body']
print(body.read())
print('File Read')
input('Press Enter to continue...\n')
# Stream File - Useful for Larger Files
object = s3.Object(bucket_name, object_name)
body = object.get()['Body']
with io.FileIO('/tmp/sample.txt', 'w') as tmp_file:
while file.write(body.read(amt=512)):
pass
print('File Streamed @ /tmp/sample.txt')
input('Press Enter to continue...\n')
# Write File
s3.Object(bucket_name, 'aws-write-test.txt').put(Body=open('./aws-write-test.txt', 'rb'))
print('File Written')
input('Press Enter to continue...\n')
# Delete File
s3.Object(bucket_name, 'aws_write_test.txt').delete()
print('File Deleted')
input('Press Enter to continue...\n')
# Stream Write File
# Create Bucket
s3.create_bucket(Bucket='new-bucket')
print('Bucket Created')
input('Press Enter to continue...\n')
# Delete Bucket
bucket_to_delete = s3.Bucket('new-bucket')
for key in bucket_to_delete.objects.all():
key.delete()
bucket_to_delete.delete()
print('Bucket Deleted')
input('Press Enter to continue...\n')
Rendimiento
Según el número de instancias de la puerta de enlace de Minio, el rendimiento puede variar. En términos generales, cuanto más paralelizables sean las cargas de trabajo y más puertas de enlace frente a Qumulo, mejor será el rendimiento. Para ayudar a los clientes a evaluar si Minio podría ayudarlos o no, publicamos los resultados de nuestras pruebas de rendimiento y nuestra metodología de prueba.
Entorno de prueba
- Nodos Qumulo: 4 x Q0626 (du19,21,23,30)
- Qumulo Client / Minio Server: 4 x uC-small (mc-14,15,18,19)
- Montajes: Cada cliente tiene cada nodo Qumulo montado con argumentos NFS predeterminados
- Servidor de Minio: instancias 4 que se ejecutan a través de Docker en cada máquina cliente con el siguiente comando
$> docker run -d -p 9000:9000 -e "MINIO_ACCESS_KEY=minio" -e "MINIO_SECRET_KEY=minio123" --name minio -v /mnt/minio-test:/nas minio/minio gateway nas /nas
Cliente de Minio (mc): Ejecutando x86 nativo en cada máquina del servidor Minio
Escritura de una sola secuencia: 84MB / s
Ceros transmitidos a Qumulo a través del comando mc pipe del cliente Minio:
$> dd if=/dev/zero bs=1M count=10000 | ./mc pipe minio1/test/10Gzeros
10000+0 records in
10000+0 records out
10485760000 bytes (10 GB) copied, 124.871 s, 84.0 MB/s
Al usar Qumulo analytics, vemos una mezcla de IOPS de lectura y escritura durante este tiempo, con las lecturas provenientes del directorio .minio.sys / multipart:
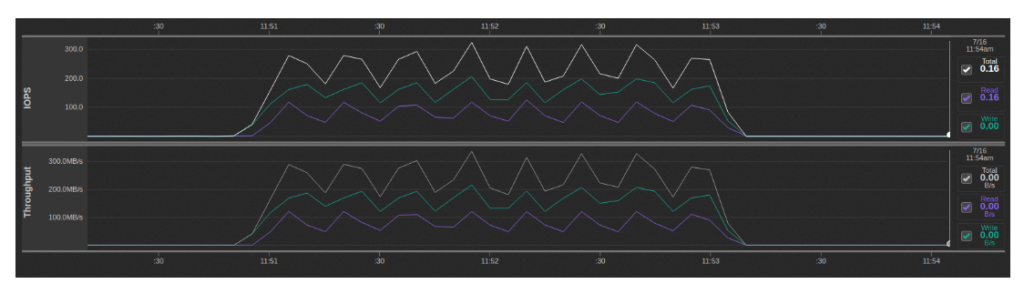
Esto se debe a la forma en que el protocolo S3 trata con archivos grandes en los que el archivo se carga en trozos y luego se vuelve a ensamblar en el archivo final de esas partes. Cuando está en el modo de puerta de enlace NAS, Minio implementa este comportamiento al hacer que cada fragmento sea su propio archivo temporal y luego leerlos y agregarlos en orden al archivo final. Esencialmente, hay un factor de amplificación de escritura de 2x y una lectura adicional de todos los datos que se escribieron.
Lectura de una sola secuencia: 643MBps
Transmití el archivo que escribí a través del comando "mc cat" de Minio, asegurándome de eliminar primero la caché del sistema de archivos de Linux y la caché de Qumulo:
$> /opt/qumulo/qq_internal cache_clear
$> echo 1 > /proc/sys/vm/drop_caches
$> ./mc cat minio1/test/10Gzeros | dd of=/dev/null bs=1M
524+274771 records in
524+274771 records out
10485760000 bytes (10 GB) copied, 16.3165 s, 643 MB/s
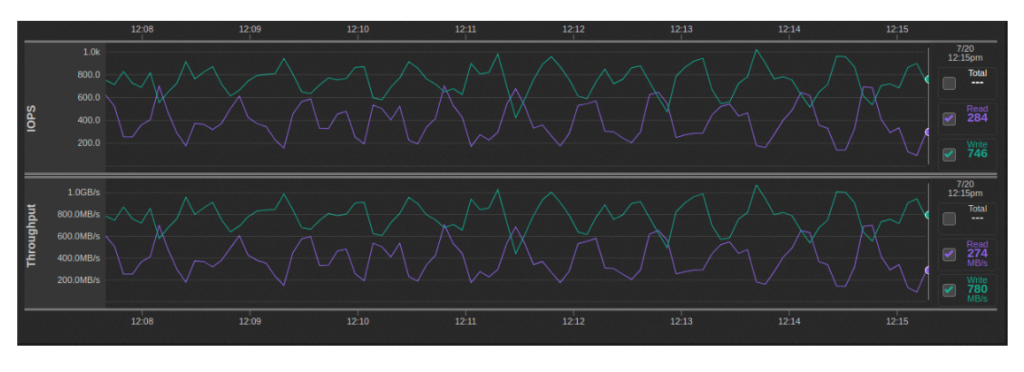
Escritura Mutli-Stream: ~ 600MBps-1GBps
Esta prueba se ejecutó con secuencias de escritura 32 10GB ejecutadas en paralelo de la manera descrita anteriormente (2 por instancia de Minio):
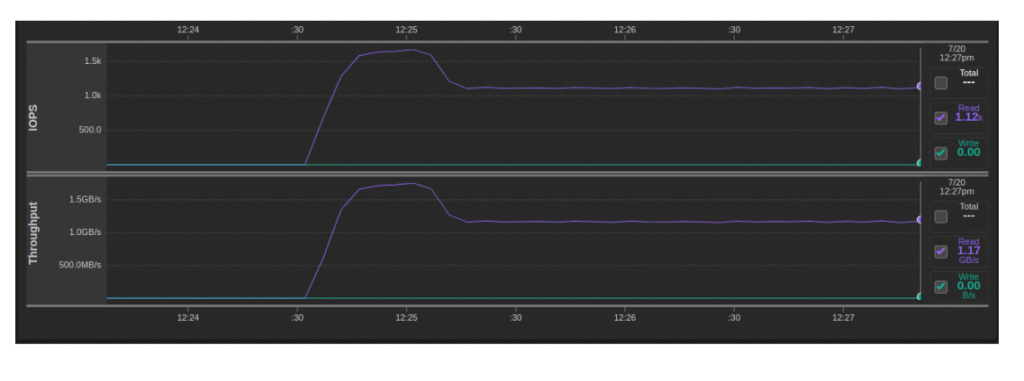
Lectura Multi-Stream: 1.1-1.7GBps
Esta prueba se ejecutó con secuencias de lectura 32 10GB que se ejecutan en paralelo de la manera descrita anteriormente (2 por instancia de Minio):
Benchmarks S3
Usar Versión modificada de minio of La prueba S3 de Wasabi Tech, pudimos producir los siguientes resultados de nuestro entorno de prueba. El punto de referencia debía modificarse porque el original asume el soporte para el control de versiones de objetos, que Minio en el modo de puerta de enlace no admite.
Cliente soltero
Esta prueba se ejecutó con secuencias de escritura 32 10GB ejecutadas en paralelo de la manera descrita anteriormente (2 por instancia de Minio):
$> ./s3-benchmark -a minio -s minio123 -u http://localhost:9001 -t 100
Wasabi benchmark program v2.0
Parameters: url=http://localhost:9001, bucket=wasabi-benchmark-bucket, duration=60, threads=100, loops=1, size=1M
Loop 1: PUT time 60.2 secs, objects = 7562, speed = 125.5MB/sec, 125.5 operations/sec.
Loop 1: GET time 60.2 secs, objects = 23535, speed = 390.8MB/sec, 390.8 operations/sec.
Loop 1: DELETE time 17.7 secs, 427.9 deletes/sec.
Benchmark completed.
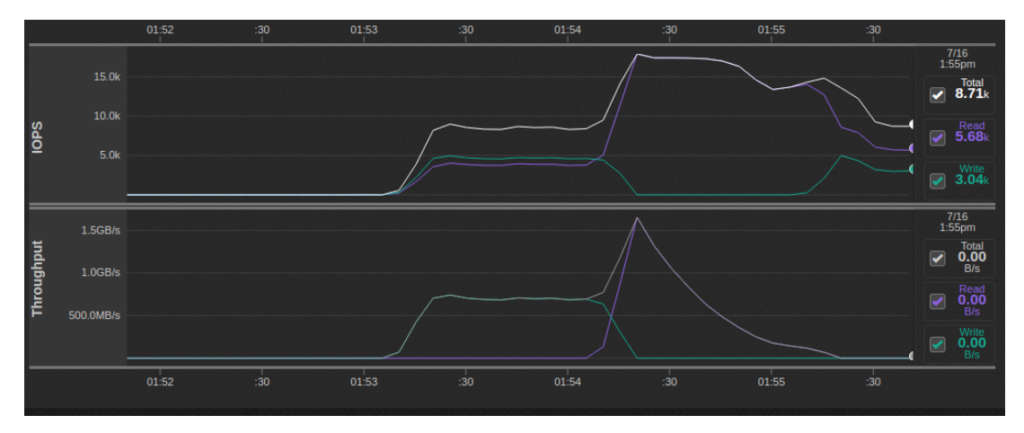
Multi-cliente
En esta variante de la prueba, ejecutamos una instancia de s3-benchmark por instancia de Minio para un total de instancias concurrentes de 16. A cada ejecución de s3-benchmark se le asignó su propio grupo. En conjunto, las velocidades de escritura parecieron alcanzar aproximadamente ~ 700MBps mientras que las velocidades de lectura alcanzaron su punto máximo en 1.5GBps y luego se redujeron:
Al aumentar el tamaño del archivo a 16MiB, pude alcanzar el rendimiento de escritura agregado de 1.5-1.8 GBps y el rendimiento de lectura agregado de 2.5 GBps en el pico. Es posible un mayor rendimiento de escritura especificando más subprocesos, pero Minio comenzó a devolver los errores de 503, lo que es probablemente el resultado de la ejecución de cuatro contenedores de Minio por máquina cliente.
El siguiente script de Bash se ejecutó en cada una de las máquinas cliente:
for i in $(seq 1 4); do
s3-benchmark/s3-benchmark -a minio -s minio123 -u http://localhost:900$i -b $HOSTNAME-$i -t 20 -z 16M &
done;
Compatibilidad S3
Minio no admite las siguientes API de S3.
API de cubo
- BucketACL (Uso políticas de cubo en lugar)
- BucketCORS (CORS habilitado de forma predeterminada en todos los grupos para todos los verbos HTTP)
- BucketLifecycle (No se requiere para el backend codificado con borrado de Minio)
- BucketReplication (Uso mc espejo en lugar)
- BucketVersions, BucketVersioning (Uso s3git)
- BucketWebsite (Uso Caddie or nginx)
- BucketAnalytics, BucketMetrics, BucketLogging (Uso notificación de cubo APIs)
- BucketRequestPayment
- BucketTagging
API de objetos
- ObjectACL (Uso políticas de cubo en lugar)
- ObjectTorrent
- ObjectVersions
Restricciones de nombre de objeto en Minio
Los nombres de objeto que contienen caracteres `^ * |" no son compatibles con Windows y otros sistemas de archivos que no admiten nombres de archivo con estos caracteres.
2. Aparece un cuadro de diálogo de confirmación. Haga clic en Sí, eliminar.