Eficiencia de almacenamiento con Qumulo
Cuando Qumulo le dice la capacidad utilizable de su sistema de almacenamiento, nos referimos exactamente a eso: esta es la capacidad que puede utilizar para almacenar archivos. Parece sencillo, pero esta es una afirmación que muchos competidores no pueden hacer. De hecho, teniendo en cuenta las ineficiencias de los métodos tradicionales de protección de datos y los problemas de rendimiento que pueden surgir con la utilización completa, la mayoría de los proveedores de almacenamiento hacen que deje hasta el 30 por ciento de su capacidad sin utilizar. En un mundo donde necesita todos sus datos al alcance de su mano, ese es un gran déficit.
Nos gustaría explicar cómo Qumulo hace posible confiar en toda su capacidad utilizable para archivos, incluso a escala de petabytes, sin sacrificar el rendimiento ni la protección de datos. Eso es cierto sin importar cuántos archivos almacene o cuán grandes o pequeños sean. De hecho, puede almacenar miles de millones de archivos pequeños con la misma eficacia que los grandes. Es su almacenamiento: puede usarlo de la forma que su empresa exija y puede usar todo ello. Después de todo, la administración del almacenamiento puede ser lo suficientemente desafiante sin tener que preguntarse si la "capacidad utilizable" realmente significa lo que se supone que debe hacer.
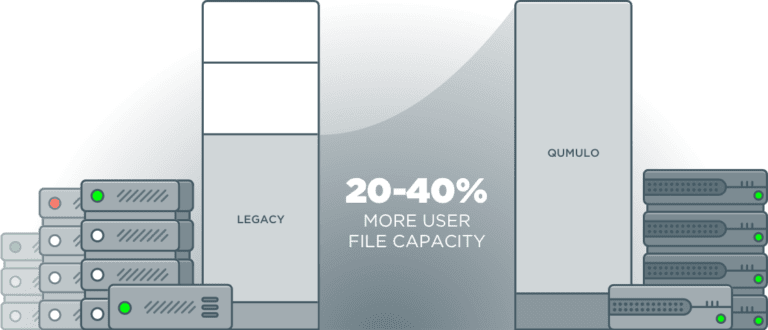
¿Por qué las soluciones de almacenamiento de escalamiento legado se crean para la capacidad desperdiciada?
La diferencia entre Qumulo y los proveedores de almacenamiento tradicionales está profundamente arraigada, como resultado de diferencias fundamentales en sus enfoques de protección de datos, almacenamiento de archivos pequeños y operaciones de reconstrucción. Vamos a discutir estos uno por uno.
Protección de datos tradicional: de ineficiente a poco menos ineficiente
La protección de datos es claramente no negociable. Todos los sistemas de almacenamiento de archivos de nivel empresarial están diseñados para evitar la pérdida de datos si fallan los discos, y todos dependen de algún tipo de redundancia o duplicación de información en los dispositivos de almacenamiento. Sin embargo, el enfoque utilizado hace una gran diferencia en la eficiencia de la protección de datos, definida como la cantidad de datos almacenados dividida por la capacidad total de disco utilizada.
Reflejando, la forma más rudimentaria de protección de datos, se basa en la creación de dos o más copias completas de los datos protegidos. Cada copia reside en un disco diferente para que sea recuperable si falla uno de los discos. Esto es efectivo en términos de recuperación, pero es extremadamente ineficiente, reduciendo a la mitad la capacidad disponible para el almacenamiento de archivos.
La duplicación doble, que conserva tres copias de datos para la protección contra hasta dos fallas simultáneas de la unidad, es mucho más efectiva para fines de recuperación, pero también es mucho más ineficiente, dejando dos tercios de la capacidad "utilizable" no disponible para los archivos. En este caso, la duplicación para la protección de dos unidades requiere 3TB de capacidad sin procesar para almacenar TB de datos de archivos.
En la escala de petabyte, obviamente es preferible evitar la duplicación lo más posible para evitar perder dos tercios de su presupuesto en el almacenamiento que no puede usar para almacenar realmente los archivos.
Codificación de borrado (EC) es la alternativa más conocida para la protección de datos que es más eficiente que la duplicación, así como más rápida y más configurable. Una ventaja clave de EC es la flexibilidad que ofrece. Los administradores pueden decidir cómo lograr el equilibrio correcto entre el rendimiento, el tiempo de recuperación en el caso de medios físicos con fallas y el número de fallas simultáneas permitidas.
Al trabajar en el nivel de bloque en lugar del nivel de archivo, EC hace posible proteger los datos de manera efectiva sin tener que crear una copia individual de todo el volumen de datos. En su lugar, los datos de bloques se codifican en segmentos parcialmente redundantes que se almacenan en medios físicos separados. En el ejemplo más simple, conocido como codificación (3, 2), se utilizan tres bloques de almacenamiento para codificar de forma segura dos bloques de datos de usuario; el tercer bloque, conocido como "bloque de paridad", se utiliza para la recuperación.
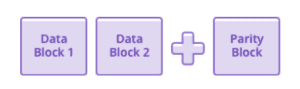
El contenido del bloque de paridad se calcula mediante el algoritmo de codificación de borrado. Incluso este esquema simple es más eficiente que la duplicación: solo está escribiendo un bloque de paridad por cada dos bloques de datos. En una codificación (3, 2), si falla el disco que contiene cualquiera de los tres bloques, los datos del usuario en los bloques 1 y 2 están seguros.
Así es como funciona. Si el bloque de datos 1 está disponible, simplemente lo lee. Lo mismo es cierto para el bloque de datos 2. Sin embargo, si el bloque de datos 1 se ha perdido, el sistema EC lee el bloque de datos 2 y el bloque de paridad, y luego reconstruye el valor del bloque de datos 1. De manera similar, si el bloque de datos 2 reside en el disco defectuoso, los sistemas leen el bloque de datos 1 y el bloque de paridad.
La codificación A (3, 2) tiene una eficiencia del porcentaje de 67; en otras palabras, dos tercios de su almacenamiento disponible se pueden usar para datos del usuario, mientras que el tercio restante se usa para la protección de datos. Agregar discos puede mejorar el nivel de protección. Por ejemplo, una codificación (6, 4), que tiene el mismo porcentaje de eficiencia de 67 que (3, 2), puede tolerar dos fallas de disco en lugar de solo una. En otras palabras, incluso si dos discos fallan al mismo tiempo, el sistema aún puede funcionar sin tiempo de inactividad o pérdida de datos. La protección adicional sin reducir la eficiencia no es un almuerzo gratis: el proceso de recuperación de los datos codificados (6, 4) requiere más trabajo que en el caso de la codificación (3, 2), lo que significa que el tiempo de reconstrucción es mayor .
En el almacenamiento de nivel empresarial, EC puede proporcionar eficiencias muy altas. Por ejemplo, la codificación (16, 14) tiene una eficiencia de aproximadamente 85 por ciento, y aún permite hasta dos fallas de unidades simultáneas sin pérdida de datos.
En este punto, ese porcentaje de eficiencia de almacenamiento de 85 puede parecer bastante bueno, especialmente en comparación con el porcentaje de eficiencia de 33 de la protección de dos unidades que utiliza la duplicación. Si necesita almacenar aproximadamente 1PB de archivos, 1.2PB de capacidad en bruto debería cubrirlo, ¿verdad? No necesariamente. Una vez más, la realidad detrás de los números es menos clara de lo que parece.
Almacenamiento de archivos pequeños: otra manera en que los proveedores heredados no cumplen con la capacidad de uso
Si bien su proveedor de almacenamiento puede reportar la capacidad utilizable como todo lo que queda después de permitir el borrado de bits de paridad de codificación, no asuma que realmente puede usar todo este espacio. Resulta que los sistemas de almacenamiento de escalamiento heredados no hacen un buen trabajo cuando se trata de archivos pequeños. Por pequeño, queremos decir cualquier cosa bajo 128KB.
Hay una razón simple para esto. Los sistemas de almacenamiento heredados se basan en un diseño de décadas de antigüedad que los obliga a duplicar (o duplicar o incluso duplicar) archivos más pequeños que 128KB. Ya hemos discutido las ineficiencias de la duplicación: ahora resulta que pueden ser un problema incluso con la protección de datos de la CE. Aquí está la peor parte: el espacio necesario para esta duplicación se deduce de la capacidad utilizable reportada por el proveedor. Es como comprar un sándwich y luego descubrir, cuando lo desenvuelves, que falta un gran bocado.
¿Qué tan grande es ese bocado que falta? Ese es otro problema: no tienes forma de saberlo. Tendría que determinar por adelantado el tamaño exacto de cada archivo que planea escribir para ver cuántos caen por debajo de ese umbral de 128KB, y no hay manera de predecirlo. Como resultado, es imposible saber cuánta capacidad útil tiene realmente o cuándo se agotará. En su lugar, tendrás que proporcionar una provisión excesiva para asegurarte de que estás cubierto. Eso significa que en realidad está desperdiciando dinero de dos formas: una, por la capacidad "utilizable" que está perdiendo por la pequeña característica del almacenamiento de archivos, y dos, por la capacidad adicional que está comprando como amortiguador.
Esa no es una manera de ejecutar un negocio intensivo de datos.
Operaciones de reconstrucción: el costo oculto de la recuperación de disco
Los proveedores de almacenamiento heredados pueden tener una forma más de recuperar su capacidad de uso prometida. Muchos sistemas consumen capacidad de almacenamiento para reconstruir operaciones mientras se recuperan de una falla del disco, y si no hay suficiente capacidad disponible para esto, el sistema tendrá dificultades para completar la recuperación. Por esta razón, la mayoría de los proveedores recomiendan que limite su utilización al 80 por ciento de la capacidad utilizable que prometieron. De nuevo, esto pone en tela de juicio la definición del proveedor de la palabra "utilizable".
Cómo es diferente Qumulo: capacidad utilizable significa capacidad utilizable
Qumulo es un tipo diferente de empresa de almacenamiento de archivos. Creemos que la capacidad utilizable significa precisamente eso: la cantidad de espacio en la que puede confiar para almacenar archivos. Con Qumulo's Sistema de archivos moderno y escalable., puede utilizar 100 por ciento de la capacidad utilizable para archivos. Este es el por qué.
Protección de datos a nivel de bloque más inteligente
Mientras que los proveedores de almacenamiento heredados se centran en mejoras incrementales en la eficiencia, Qumulo ha interrumpido la industria con un enfoque fundamentalmente diferente. En lugar de proteger los datos a nivel de archivo como lo hacen otros, Qumulo protege en el nivel de archivo. nivel de bloque, permitiendo ganancias típicas de 20 por ciento en la capacidad de uso para archivos grandes. Y esa cifra se duplica cuando entran pequeños archivos en la imagen.
Almacenamiento de archivos pequeños de alta eficiencia
Al administrar archivos pequeños, la protección a nivel de bloque ofrece una eficiencia de almacenamiento de hasta un 40 por ciento más allá de la protección basada en archivos. Esto es especialmente valioso en una era de datos generados por una máquina, que generalmente viene en forma de una gran cantidad de archivos pequeños.
Aquí hay un ejemplo de un cliente empresarial real (antes de llegar a Qumulo).
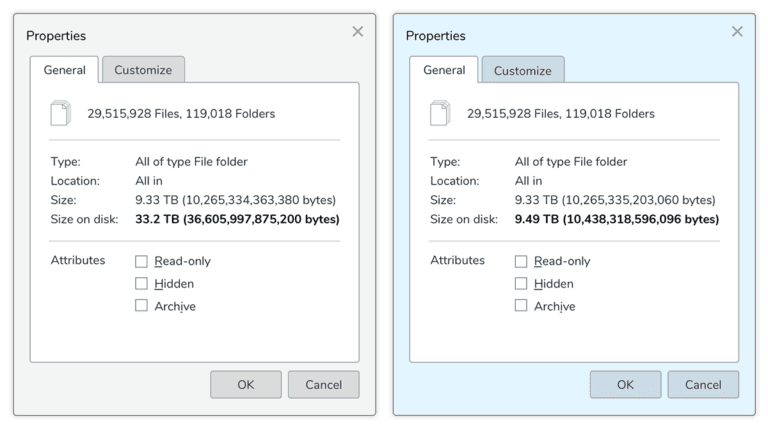
Este cliente migró alrededor de 30 millones de archivos pequeños de un clúster de almacenamiento heredado a un clúster Qumulo. El cuadro de diálogo de la izquierda muestra la cantidad de espacio que estos archivos ocuparon en el sistema del proveedor heredado, que refleja los archivos pequeños. El cuadro de la derecha muestra la cantidad de espacio que ocupan los archivos en el clúster Qumulo. Como puede ver, el sistema del proveedor legado necesitó más de tres veces más espacio para almacenar los mismos archivos: un 33.2TB completo de capacidad utilizable para 9.33TB de datos de archivos. En el clúster de Qumulo, solo tomó 9.49TB.
Eso es lo que más me gusta.
De hecho, con Qumulo, no hay diferencia en la eficiencia de almacenamiento entre archivos grandes y pequeños.
Eso hace que sea mucho más sencillo estimar cuánto almacenamiento necesitará. En lugar de luchar con estimaciones complejas de la combinación de archivos grandes y pequeños en sus cargas de trabajo y con la esperanza de que no estén demasiado lejos de la marca, puede mirar la interfaz de usuario web para ver cuánto espacio hay disponible. Sus archivos almacenados ocuparán la misma cantidad de espacio, independientemente de cuántos sean grandes o pequeños.
Reconstruir las operaciones que no reducen la capacidad utilizable
Con Qumulo, no es necesario dejar de lado la capacidad utilizable para tareas administrativas, como las reconstrucciones. En su lugar, el sistema deja de lado el espacio que necesita antes de informar la capacidad utilizable. Eso significa que puede recuperarse de las fallas de la unidad incluso si el sistema tiene un porcentaje de 100 completo, y sin tener que monitorear el espacio libre. Qumulo también proporciona reconstrucciones más rápidas que el RAID tradicional, y no introduce puntos de acceso de rendimiento después de una falla en la unidad.
Máximo rendimiento con un porcentaje de utilización de 100
El compromiso entre la utilización y el rendimiento es demasiado familiar para los administradores de almacenamiento. Muchos sistemas de escalado, RAIDbasados en sistemas, y algunos de los sistemas de archivos de código abierto más populares experimentan una degradación del rendimiento a medida que el sistema de archivos se llena. Para evitar problemas de rendimiento, se supone que debe permanecer bajo 70 por ciento de la capacidad utilizable. No debería tener que elegir entre la utilización y el rendimiento, pero esa es la posición que le asignan muchos proveedores.
A diferencia de otros sistemas, el rendimiento de Qumulo no se degrada a medida que su sistema se llena. En lugar de mantener el 30 por ciento de su capacidad en reserva, puede seguir adelante y utilizar el 100 por ciento de ella, almacenando miles de millones de archivos sin impacto en el rendimiento.
Que significa Qumulo para sus datos
En total, los beneficios de eficiencia combinados significan que un cliente típico de Qumulo puede almacenar la misma cantidad de datos de usuario con 25 por ciento menos capacidad bruta que otros sistemas de archivos.
Esa alta eficiencia se complementa con los beneficios que importan a las empresas que utilizan muchos datos:
- Tiempos de reconstrucción rápidos en caso de una unidad de disco fallida
- La capacidad de continuar operaciones normales de archivos durante las operaciones de reconstrucción
- Sin degradación del rendimiento debido a la contención entre las escrituras de archivo normales y las escrituras de reconstrucción
- Igual eficiencia de almacenamiento para archivos pequeños y grandes
- Informes precisos del espacio utilizable
- Transacciones eficientes que permiten a los clústeres Qumulo escalar a muchos cientos de nodos
- Niveles incorporados de datos fríos / calientes que proporcionan un rendimiento de flash a precios de archivo.
Sus datos son demasiado importantes como para dejarlos obsoletos en los métodos de almacenamiento heredados, o para los proveedores que tienen un gran control sobre el concepto de "capacidad utilizable". Qumulo ofrece la transparencia, previsibilidad y rendimiento que necesita para las operaciones de datos de la era digital.