
El mundo de la inteligencia artificial (IA) ha experimentado un crecimiento exponencial y tiene un hambre insaciable de consumir datos. Desde vehículos autónomos hasta chatbots que imitan la conversación humana, la IA está revolucionando las industrias a un ritmo vertiginoso. El poder de la IA se deriva de su columna vertebral de datos. El acceso a los datos, la velocidad de su procesamiento y el rendimiento del almacenamiento escalable son factores fundamentales que determinan la eficiencia de un canal de IA. Aquí es donde Qumulo ha demostrado ser la mejor solución de almacenamiento de datos del planeta para cargas de trabajo de IA, como la solución de datos de archivos en la nube de mayor rendimiento y más rentable de la industria.
Por qué Qumulo es ideal para cargas de trabajo de IA basadas en archivos
Las aplicaciones de IA, ya sean modelos de aprendizaje profundo o redes neuronales, requieren un conjunto único de características de almacenamiento, todas las cuales son satisfechas por Qumulo:
- Escalabilidad: Los conjuntos de datos de IA son dinámicos. Crecen con el tiempo a medida que se recopilan y procesan más datos. La capacidad de Qumulo para escalar con un alto rendimiento predecible garantiza que a medida que crezcan las cargas de trabajo de IA, Qumulo pueda satisfacer sus demandas a cualquier escala.
- Rentabilidad: Financiar iniciativas de IA puede ser una inversión importante. Ahorrar en costos de almacenamiento sin comprometer el rendimiento puede liberar recursos para otras áreas críticas, ya sea investigación, desarrollo o implementaciones de producción.
- Capacidad de escalar en cualquier lugarTM: Los propietarios de infraestructuras y los científicos de datos se benefician de la flexibilidad de la capacitación en un lugar, pero la implementación en otro, con una infraestructura altamente segura. El sistema de almacenamiento definido por software de Qumulo se puede implementar y ejecutar en cualquier lugar. Esto facilita entrenar un modelo de IA en el centro de datos central, pero llevarlo a producción en cualquier lugar.
- Actuación: Los modelos de IA, especialmente aquellos utilizados en escenarios como vehículos autónomos o transacciones financieras, necesitan acceso a datos en tiempo real para el entrenamiento previo y posterior al modelo. La recuperación de datos de alta velocidad de Qumulo garantiza que los datos estén disponibles en el momento en que se requiere.
Profundicemos en el punto 4 y subrayemos la importancia de una recuperación de datos/metadatos fluida y ultrarrápida. Esto es vital para las aplicaciones de IA que requieren almacenamiento de archivos escalable, ya sea local o en la nube.
Al probar cargas de trabajo de IA sintética, descubrimos que, de hecho, somos la solución en la nube basada en archivos más rápida del mercado para IA, donde los científicos de datos pueden usar Qumulo para la recopilación de datos, la capacitación previa, la capacitación en producción y la inferencia continua, sin importar la escala. .
Leyendo.
Punto de referencia de IA ampliamente aplicable
Para poner en perspectiva las capacidades de rendimiento de Qumulo, profundicemos en el último resultado logrado con Qumulo ejecutándose en la nube en la infraestructura de AWS. Usamos SPECstorage para caracterizar el rendimiento de la IA en Qumulo. Este punto de referencia (acertadamente llamado AI_Image) aprovecha los tamaños de archivos y los patrones de E/S que ejercitan de forma sintética y precisa cargas de trabajo comunes de IA:
- Basado en Tensorflow y las mejores prácticas – el marco de IA/ML más implementado del mundo
- Trazado a partir de 3 modelos diferentes: Resnet, VGG (Visual Geometry Group) y SSD (detector de disparo único)
- Uso de conjuntos de datos de código abierto de CityScape, ImageNet y COCO
Debido a la ubicuidad de Tensorflow en el espacio de la IA, el punto de referencia se aplica a una amplia gama de cargas de trabajo de modelos de IA que producen resultados de IA para:
- Clasificación de imágenes y detección de objetos
- Procesamiento del lenguaje natural (PNL)
- Reconocimiento de voz
- Sistemas de recomendación
- Modelos generativos
- Salud y ciencias de la vida
…y muchos más
Descripción del punto de referencia y resultados obtenidos
El objetivo del punto de referencia es entregar datos rápidamente desde el almacenamiento Qumulo a la capa de aplicación (usando GPU) que ejecuta los trabajos de IA. El punto de referencia prueba el rendimiento del almacenamiento y la latencia a partir de un conjunto realista de patrones de E/S de un lote de clientes. Los clientes aumentan progresivamente su número de trabajos de IA hasta alcanzar el objetivo, que en el caso de esta prueba es un total de 480 trabajos. Hay cuatro operaciones principales en el punto de referencia, con 4 subcargas de trabajo simultáneas e independientes:
- AI_SF – Lecturas de archivos de imágenes pequeños
- AI_TF: escribe archivos más grandes (idealmente archivos de más de 100 MB)
- AI_TR: lee en TFRecords grandes
- AI_CP: realiza puntos de control ocasionales
Resultados
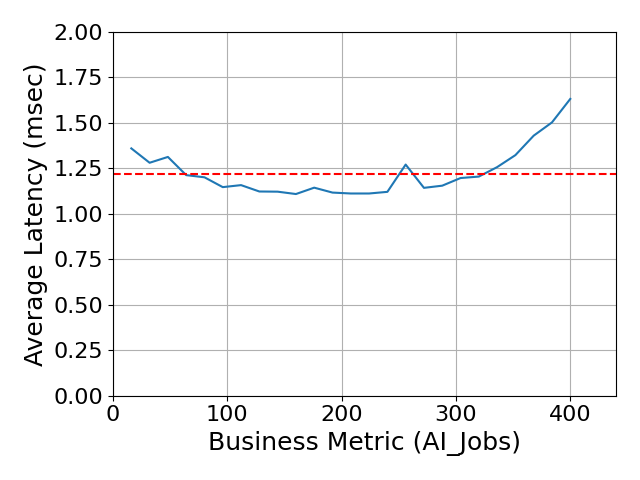
La figura 1 a continuación muestra los siguientes resultados:
- El eje X muestra la cantidad de trabajos que ejecutan el punto de referencia de IA a lo largo del tiempo
- El eje Y muestra la latencia general durante la duración de la prueba.
- ¡La latencia muestra que el rendimiento del almacenamiento es rápido y predecible a medida que aumenta la cantidad de trabajos de IA!
** Comparación basada en sistemas de mejor rendimiento en nubes públicas publicada en www.spec.org a octubre de 2023. SPEC® y el nombre de referencia SPECgeneric® son marcas comerciales registradas de Standard Performance Assessment Corporation. Para obtener más información sobre SPECstorage2020, consulte https://www.spec.org/storage2020/.
Aplicabilidad local
Si bien las pruebas comparativas de SPECstorage utilizaron un entorno basado en la nube, estos resultados se pueden extrapolar fácilmente para estimar resultados utilizando hardware local similar. Cuando Qumulo publique este punto de referencia en el sitio web de SPEC (ETA diciembre/2023), se podrán encontrar los detalles y el costo del entorno, observando los tipos de instancias EC2 (número de núcleos, memoria disponible, etc.) utilizados y el ancho de banda disponible en la red. ambiente. Mientras tanto, incluimos detalles adicionales en el apéndice de este blog para lectores curiosos.
Científicos de datos e ingenieros de datos, he aquí. ¡Inténtalo tú mismo!
En el mundo de la IA, que avanza rápidamente, tener una solución de almacenamiento sólida, rápida y escalable no es un lujo sino una necesidad. Qumulo, con su rendimiento y rentabilidad líderes en la industria, se destaca como la solución de archivos basada en la nube para cargas de trabajo de IA. El punto de referencia no solo subraya la destreza de Qumulo, sino que también consolida su posición como la solución de almacenamiento para IA más rápida y de mayor aplicación.
See resultados completos publicado en Spec.org
Apéndice
Rendimiento
Tiempo de respuesta total = 1.22 ms
|
Información de producto y prueba
| Qumulo – Referencia de nube pública | |
|---|---|
| Probado por | Qumulo, Inc. |
| Hardware disponible | Noviembre 2023 |
| Software disponible | Noviembre 2023 |
| Fecha de prueba | Noviembre 2023 |
| Número de licencia | 6738 |
| Ubicaciones del licenciatario | Seattle, WA EE. UU. |
Qumulo es una solución híbrida de almacenamiento de archivos en la nube que cuenta con una escalabilidad superior a exabytes en un único espacio de nombres, características idénticas ya sea localmente o en la nube y soporte multiprotocolo completo, lo que garantiza flexibilidad y compatibilidad entre diversas aplicaciones. Al integrarse perfectamente con la infraestructura de la nube pública, Qumulo ofrece almacenamiento de datos no estructurados a cualquier escala, con visibilidad en tiempo real del rendimiento del almacenamiento y el uso de datos.
El sistema de archivos nativo de la nube de Qumulo permite a las organizaciones migrar sin problemas aplicaciones y cargas de trabajo basadas en archivos al entorno de la nube pública. Con Qumulo, las empresas pueden gestionar de manera eficiente exabytes de datos, ya sea localmente o en la nube. Los siguientes hallazgos demuestran claramente que el sistema de archivos Qumulo destaca por ofrecer un rendimiento excepcional cuando se implementa en AWS.
Solución bajo prueba Lista de materiales
| Artículo No | Cantidad | Tipo de Propiedad | Proveedor | Nombre del modelo | Descripción |
|---|---|---|---|---|---|
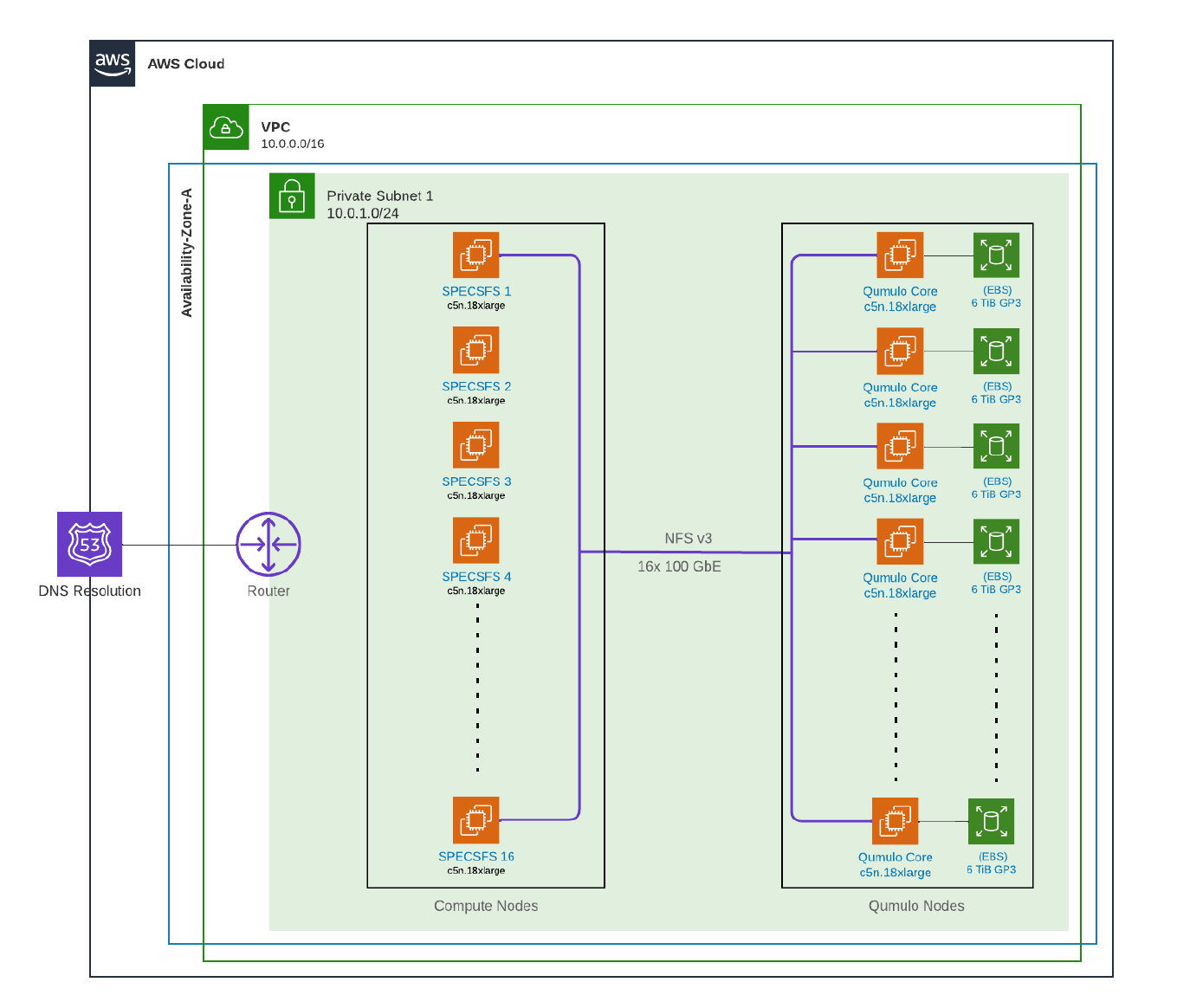
| 1 | 16 | Instancias AWS EC2 | AWS | c5n.18xgrande | Nodos Qumulo: instancias Amazon c5n EC2 (las instancias c5n.18xlarge tienen 72 vCPU, 192 GiB de memoria y red de 100 Gbps) |
| 2 | 16 | Instancias AWS EC2 | AWS | c5n.18xgrande | Clientes Ubuntu – Clúster Qumulo – Instancias Amazon c5n EC2 (las instancias c5n.18xlarge tienen 72 vCPU, 192 GiB de memoria, red de 100 Gbps) |
Diagramas de configuración
Qumulo en AWS
software componente
| Artículo No | Componente | Tipo de Propiedad | Nombre y versión | Descripción |
|---|---|---|---|---|
| 1 | Qumulo Core | Sistema de archivos | 6.2.2 | El sistema de archivos nativo de la nube de Qumulo permite a las organizaciones mover sin esfuerzo aplicaciones y cargas de trabajo basadas en archivos a la nube pública. |
| 2 | Ubuntu | Sistema operativo | 22.04 | El sistema operativo Ubuntu se implementa en los dieciséis nodos informáticos c5n.18xlarge. Se utilizan como clientes que ejecutan los puntos de referencia de SPEC Storage 2020. |
Configuración y ajuste de hardware: físico
| Nombre del componente | ||
|---|---|---|
| Nombre del parámetro | Valor | Descripción |
| SR-IOV | implante | Habilita la tecnología de virtualización de CPU. |
| Velocidad del puerto | 100 GbE | Cada nodo tiene conectividad de 100 GbE |
Notas de configuración y ajuste de hardware
Ninguna
Configuración y ajuste del software: virtual
| Networking | ||
|---|---|---|
| Nombre del parámetro | Valor | Descripción |
| Tramas gigantes | 9001 | Permite tramas gigantes Ethernet de hasta 9001 bytes |
| Parámetros de montaje NFS de clientes Ubuntu | ||
| Nombre del parámetro | Valor | Descripción |
| a | 3 | Utilice NFSv3 |
| desconectar | 16 | Aumentar el número de conexiones de clientes NFS hasta 16 |
| tcp | Protocolo de transporte de red TCP para comunicarse con el clúster Qumulo | |
| bloqueo_local | todos | El cliente asume que tanto los bloqueos Flock como POSIX son locales. |
| Parámetro de volumen de EBS | ||
| Nombre del parámetro | Valor | Descripción |
| IOPS | 16000 | IOPS máx. para volumen de EBS |
| rendimiento | 1000 | Rendimiento máximo para el volumen de EBS |
Notas de configuración y ajuste del software
Ninguna
Notas del SLA de servicio
AWS realiza esfuerzos comercialmente razonables para que los Productos y Servicios incluidos estén disponibles con un porcentaje de tiempo de actividad mensual de al menos el 99.99 %, en cada caso durante cualquier ciclo de facturación mensual. El Porcentaje de Tiempo de Actividad Mensual se calcula restando del 100% el porcentaje de minutos durante el mes en el que cualquiera de los Productos y Servicios Incluidos, según corresponda, estuvo en el estado de “Región No Disponible”.
Almacenamiento y sistemas de archivos
| Artículo No | Descripción | Protección de Datos | Almacenamiento estable | Cantidad |
|---|---|---|---|---|
| 1 | Volumen de Elastic Block Storage, capacidad de 1TB gp3. Cada nodo Qumulo tiene 6 volúmenes EBS. | Protección de 2 unidades o 1 nodo con codificación de borrado | EBS de AWS | 96 |
| Número de sistemas de archivos | 1 |
|---|---|
| Capacidad total | 78.54 TB |
| Tipo de sistema de archivos | Qumulo |
Notas de creación del sistema de archivos
El sistema de archivos Qumulo Core se implementa en AWS a través de una plantilla de formación de nubes o Terraform. Se implementa la AMI de Qumulo Core y el sistema de archivos se configura como parte del proceso automatizado de formación de la nube o mediante Terraform. No se requieren pasos adicionales para la creación del sistema de archivos.
Notas sobre almacenamiento y sistema de archivos
Ninguna
Configuración de transporte – Virtual
| Artículo No | Tipo de transporte | Número de puertos utilizados | Notas |
|---|---|---|---|
| 1 | NIC virtual Ethernet de 100 Gbps | 16 | Utilizado por máquinas cliente |
| 2 | NIC virtual Ethernet de 100 Gbps | 16 | Utilizado por Qumulo Core para comunicaciones entre nodos, así como para comunicaciones con cualquier cliente. |
Notas de configuración de transporte
Ninguna
Conmutadores – Virtuales
| Artículo No | Cambiar nombre | Tipo de interruptor | Recuento total de puertos | Recuento de puertos usados | Notas |
|---|---|---|---|---|---|
| 1 | AWS | Ethernet de 100 Gbps con redes mejoradas | 16 | 16 | Utilizado por máquinas cliente |
| 2 | AWS | Ethernet de 100 Gbps con redes mejoradas | 16 | 16 | Utilizado por los nodos de Qumulo Core |
Elementos de procesamiento – Virtuales
| Artículo No | Cantidad | Tipo de Propiedad | Destino | Descripción | Función de procesamiento |
|---|---|---|---|---|---|
| 1 | 1152 | CPU virtual | c5n.18xlarge Núcleo Qumulo | Procesadores Intel Xeon Platinum de 3.5 GHz | Qumulo Core, Comunicación de red, Funciones de almacenamiento |
| 2 | 1152 | CPU virtual | c5n.18xlarge Núcleo Qumulo | Procesadores Intel Xeon Platinum de 3.5 GHz | Procesadores de referencia de cliente de almacenamiento de especificaciones |
Notas sobre elementos de procesamiento
Ninguna
Memoria – Virtual
| Descripción | Tamaño en GiB | Numero de instancias | No volátil | GB totales |
|---|---|---|---|---|
| Memoria de instancia AWS EC2 c5n.18xlarge | 192 | 16 | V | 3072 |
| Memoria de instancia AWS EC2 c5n.18xlarge | 192 | 16 | V | 3072 |
| Gran total de gibibytes de memoria | 6144 | |||
Notas de memoria
Ninguna
Almacenamiento estable
Qumulo Core utiliza dispositivos Elastic Block Storage (EBS); que proporcionan un almacenamiento estable.
Notas de configuración de la solución en prueba
La solución bajo prueba fue un clúster distribuido estándar creado utilizando Qumulo Core. Los clústeres de Qumulo Core pueden manejar E/S de archivos grandes y pequeños junto con aplicaciones con uso intensivo de metadatos. No se requiere ningún ajuste especializado para cargas de trabajo diferentes o de uso mixto.

