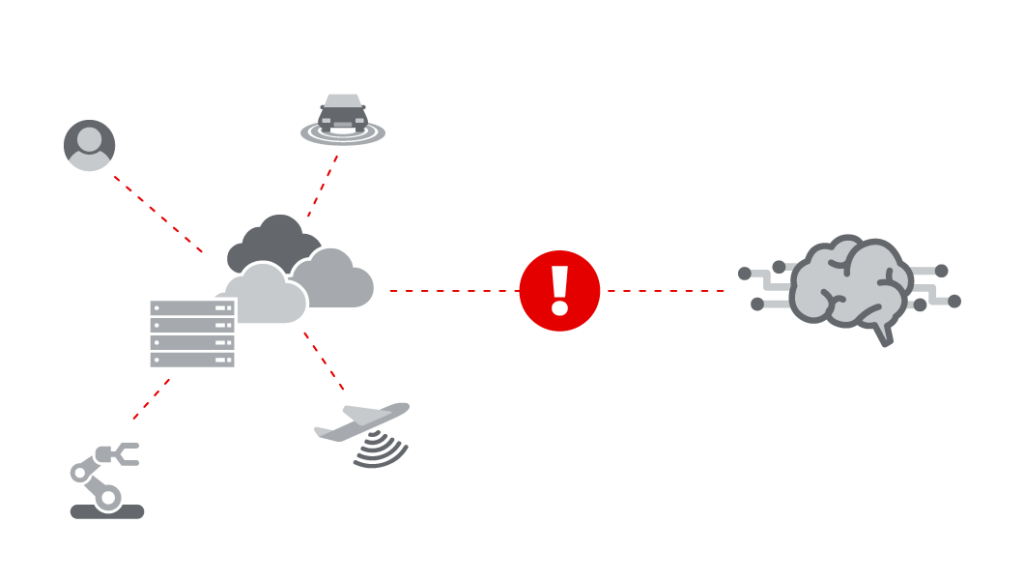
あらゆる場所で AI ワークロードを強化 AI はストレージに対して厳しい要求を課しており、それが AI の妨げとなっています。 実際、ほぼすべてのデータは構造化されていませんが、AI に使用されているデータのほとんどは構造化されていません。 、それが業界の足かせになっています。 始 め る 〜90%で すべてのデータのうち、 構造化されていない。 視聴者の38%が AI モデルを強化するデータのうち、 非構造化 視聴者の38%が の企業が、本番環境に対応したパイプラインの不足が AI 計画を遅らせていると回答しています より多くのデータ、より多くのユーザー、より多くの危険にさらされる 侵害が発生すると、組織は身代金の支払い、収益の損失、修復コストで数百万ドルの損失を被る可能性があり、言うまでもなく、長期的な風評被害も発生します. AI データ ストレージに関連するストレージに関する一般的な課題が XNUMX つあります。 データと AI エコシステムが切断されている AIに使用されるデータはエッジまたはデータセンターで生成されます。 工場の現場や自動運転車から来る IoT データを考えてみましょう。 ただし、AI エコシステムはクラウド内に存在します (AI サービス、専門家による相談など)。企業は、その貴重なデータをクラウド内の AI エコシステムの近くに配置する方法を見つける必要があります。 現在、すべての AI 非構造化データを配置することは困難です まず、非常に高価です。 第 XNUMX に、そのデータに依存するアプリは、オブジェクト データを処理できるように再プラットフォーム化する必要があります。これが、現在のクラウドにおける唯一の実際のオプションであるためです。 AI が普及するには、この状況を変える必要があります。 従来のソリューションが AI エンジンを抑制する 最新の GPU ベースの大規模並列スレッド AI ワークフローは、数万件の同時読み取りを簡単に生成できますが、多くの従来のソリューションでは同時読み取りがその数分の一に制限されています。 これにより、モデル構築が抑制されます。AI が高度に俊敏になるためには、この問題を修正する必要があります。 Qumulo が AI をどのように実現するか 私たちはこれらの障害を吹き飛ばすために Qumulo を構築しました。 その方法は次のとおりです。 。 。 Qumulo で Scale Anywhere™ を実現 Qumulo のスケールをどこでも™ プラットフォームはエッジ、コア、クラウドで実行されます。 また、Qumulo は 100% ソフトウェアのみのソリューションであるため、選択したハードウェアまたは必要なクラウドで実行できます。 これにより、貴重な非構造化データをクラウドベースの AI エコシステムのすぐ近くに配置することが簡単になります。 フルスロットル、言い訳なし、同時読み取り Qumulo は、同時に実行できる読み取り数に制限を設けたことはありません。 ファイル データ プラットフォームの制限に縛られずに、最もホットな新しい Nvidia GPU ツールとモデルを解き放ちます。 データを高度に安全に保ちます AI は大規模なデータセットに依存することが多く、そのデータセットには機密情報が含まれる場合があります。 データ侵害は、法的、経済的、評判に重大な影響を与える可能性があります。 Qumulo はトレーニングに関連するすべてのデータを保護し、保管します。 AES 256ビットソフトウェアベース 暗号化と不変スナップショット。 使用 事例 私たちはこれらの障害を吹き飛ばすために Qumulo を構築しました。 その方法は次のとおりです。 。 。 現代の製造業 あらゆる場所に設置された工場フロアのカメラは、リアルタイムの自動化された製造作業におけるあらゆる種類の情報をキャプチャします。 これらすべてはローカル ストレージ上に継続的に集約されます。 高度な目的 (自動故障検出など) の場合、運用ではすべての製造ラインからのデータが結合され、モデルのトレーニングのソースになります。 モデルが成熟すると、運用を最適化するために各工場に戻されます。 自律車両 自動運転車は、現実世界の高解像度のマルチスペクトルビデオを継続的にキャプチャします。 これは数百台の試験車両から始まり、次に数千台の実験車両、そして最後に数百万台の通常車両になります。 車はこれらのビデオを中央の場所にアップロードして、ドライバーを支援し、自動操縦を可能にし、自動運転車を実現するためにモデルをトレーニングします。 上記から派生した推論モデルは、量産車両にプッシュバックされます。 次に、モデルはリアルタイム データを処理して自動運転を最適化します。 AI支援サイバーセキュリティ Network SecOps の専門家は、数十万のネットワーク デバイス (クラウド、オンプレミス、またはその両方) からのアクティビティ ログを統合します。 これにより、不正なネットワーク侵入を検出するためのモデルのトレーニング データ セットが形成されます。 結果として得られる推論モデルは最新のネットワーク デバイスにプッシュダウンされ、リアルタイムで観察されたイベントを分析して不正侵入を発見します。 そ の 他 の リ ソ ー ス ¿Qumulo? 始 め る